
A little over a year ago I started work on Salesforce2Sql to help support people doing data work with Salesforce. Salesforce2Sql is a simple Electron app that allows you to clone the schema of a Salesforce org into an SQL database (currently supports MySql/MariaDB and Postgres). These mirrors are useful when you want to stage data during migrations in or out of Salesforce.
When is Salesforce2Sql useful
Salesforce2Sql is a tool dedicated to doing one thing very well: mirroring Salesforce schema. It does not attempt to extract data or convert data in any way.
Salesforce provides excellent APIs for data import and export, but they work best with some prep work first. Salesforce2Sql gives you a staging database that mimics your Salesforce schema. In these schema mirrors you can prepare all your data for high speed processing off-platform. Anyone who is looking to move data into or out of Salesforce at high speeds and large volumes benefits from this setup.
I have seen people write large complex ETL jobs meant to go right from one source system into Salesforce. These jobs can be hard to test and they are slow to run. They generally don’t give you an easy way to review the data before you push to Salesforce. By landing the data in a database clone you can break the jobs into stages, review transformations before they are loaded, and run thousands of iterations for testing instead of dozens.
Setup
Salesforce2Sql is built and released for MacOS, Windows, and Linux (most testing is on Mac and Windows). You can download the installers from the current release and follow the standard patterns for your OS. From there start the application to get to work.
You will also need API access to a Salesforce org and a database to create your schema within.
Basic Salesforce2Sql Use
As of this writing Salesforce2Sql uses the old security token connection method. I would like to add OAuth2 support as well but haven’t gotten that done; contributions are welcome. So with the application running, and your security token in hand, click the big “Create New Connection” button on the left side of the main interface.

Step 1: Fetch all objects
Once connected click “Fetch Objects”, and the tool will download a list of every object in your org. There will be several hundred. So the next step is to select which you want to mirror. You will notice Salesforce2Sql selected defaults for you (well I did). It will select all custom objects and based on your org’s structure Salesforce2Sql guess which standard objects to select. There is a search box at the top right to help you find any others you’d like to add but simply checking the box.
Step 2: Fetch all fields
Click the next button to move to the Proposed Schema tab, and then the “Fetch Details” button. Now Salesforce2Sql will query every field on every object you just selected (this may take a moment but honestly I find it much faster than I expected when I first started this project). Once that is complete you can either save that schema to JSON for later re-use, or click Next to move to the “Generated Database” tab.
Step 3: Generate tables
This is the last step. Click “Create Tables” and Salesforce2Sql will ask you for your database credentials. Once you click okay on this final screen the tool will attempt to create all those tables for you. Again this will take a couple minutes if you have a large schema. Once the process is complete you can also save the SQL statements for editing and/or later re-use.
That’s it, you now have a database with a schema that matches your org’s structure.
Preferences
There are a few preferences you might want to experiment with (although I tried to pick smart defaults) when building mirrors. For me the right choices depend on my use case.
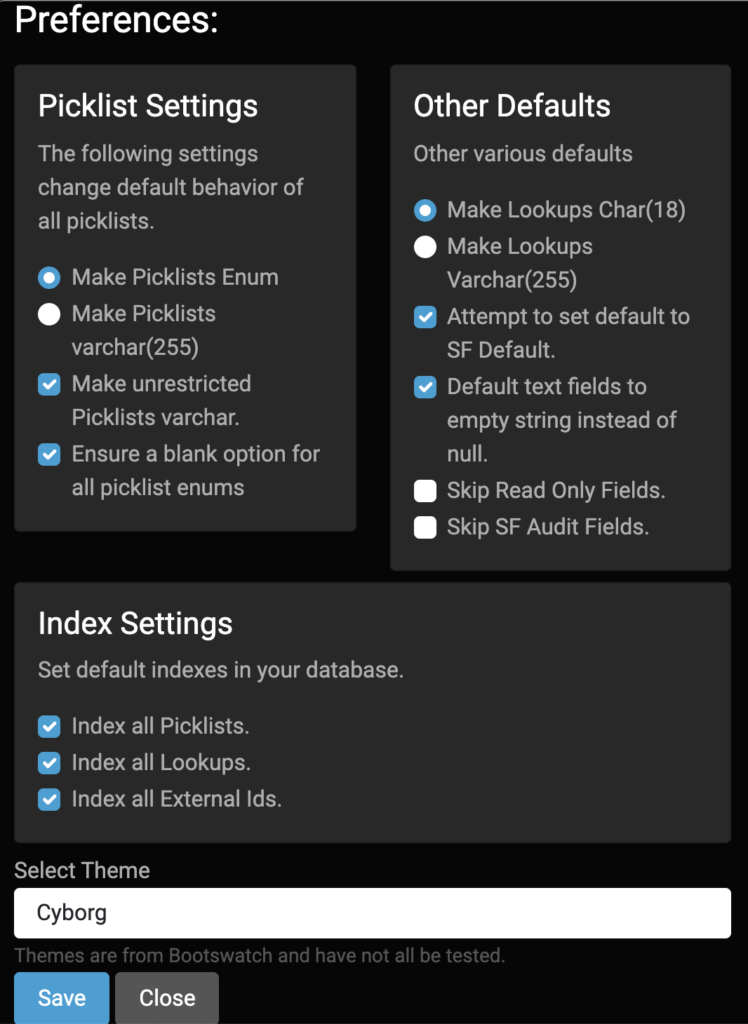
Picklists
Salesforce Picklists are a bit of a special beast. The obvious choice is to make a picklist into a SQL Enum to support validation of data. But not all picklists are restricted in Salesforce and aren’t always required. By default the tool will use enum for restricted picklists, varchar for unrestricted picklists, and add blank values to all picklists (since it can’t easily determine if a given picklist is required or not across all page layouts).
If the picklist values in your org are pretty much set, the default settings make a lot of sense. If the picklist values in your org are likely to change you might want to make them all into regular varchar columns.
Auto Indexing
The next important section contains the index settings. While it is possible to over-index a database I think the three sets of default indexes are pretty good guesses: Id columns, external Ids, and picklists. The one you are most likely not to care about are the enums, and therefore the one you might consider disabling if you aren’t processing on those fields at all. Id columns are now case-sensitive even in MySQL by default as of version 0.7.0 since Salesforce Ids are case sensitive.
Additional Settings
The other defaults section let’s you pick a few other system behaviors. The most common to fuss with are first and last in the box.
By default it expects Lookup fields to be 18 character Salesforce Ids – cause that’s what they will be in Salesforce. But during a data migration some people like to put legacy Ids into these fields (I recommend a proper legacy Id field marked as an external Id) so I give the option to use 255 characters instead of 18.
Salesforce also has two categories of fields that are common to ignore in a migration and you may wish to keep out of your database just for ease of use: the audit fields (createdBy and the like) and read-only fields (like formulas). The final two checkboxes in that other defaults section lets you keep those fields out of your clone schema.
The middle two fields control the behavior of field defaults – generally I like these two settings as is in just about every use case, but you may feel differently.
Salesforce2Sql uses Bootswatch themes for design elements. The preference pane also lets you pick a different look-and-feel from their theme list.
Final Notes
There are a couple other details worth knowing.
First, if the process runs into a problem where the SQL engine complains about row size limits Salesforce2Sql will automatically switch all varchar fields to TEXT fields in an attempt to reduce the row size. That will override all preference settings for these fields.
Second, Knex.js – which Salesforce2Sql uses to handle the actual SQL writing – adds indexes as a table alter even when they could be part of the create statement. This makes the process a bit slow and it means that if there are errors during the creation of indexes you may see some errors in the interface but leave you with a pretty-good schema clone.
Finally, yes there is lots of room for improvement. I work on this project when I can, or when I need a bug fixed for my own work. I am excited to get suggestions, ideas, feedback, documentation edits, and code submissions.