This week I was working with a new colleague on our account team. As with all people knew to working with technical teams and bug tracking, she’s having to learn how to create good trouble tickets for when clients report issues. This is a challenge I’ve seen played out in every place I’ve ever worked: developers want detailed tickets so we can dive in without asking 16 follow up questions, and people creating tickets don’t actually know what we want and assume we know how to find and fix the problem. And so I’d like to try to offer this explanation of what we’re looking for and why.
At the most basic level I need to know at least three things to find and fix a problem on a project (either a web site or some other tool I’m supporting):
Where in the program is the problem? This is usually a link to a sample page that has the problem.
What happened? I need a clear explanation of what went wrong. Is there a picture missing? Is the text format wrong? Is there a big red error message at the top?
What you expected to happen? What is the picture of and where exactly was the picture supposed to appear? What formatting was supposed to appear on the text? Did you do something right before the error message appeared that helps me see that message again?
These things are part of allowing me to reproduce the problem. If I can’t reproduce the problem, I can’t promise you I fixed it. If you can’t reproduce the problem, you can’t check that I’m right.
Developers will often say that if you can’t give me the step to reproduce a problem I can’t fix it. But in my experience sometimes a problem is actually really hard to reproduce, and you need a developer or a professional tester to actually figure out those steps. So it’s okay if you can’t give me perfect directions, but give me what you have.
If you find yourself writing a ticket that doesn’t say more than “Search is broken” or “Blog post didn’t look right” the problem better be massive (think big red error message level). As an account/support team member that may be all you got from the client but someone has to fill the gaps – and developers are terrible people to have fill those gaps.
As a developer there are several reasons that’s true.
First, rarely do developers get the luxury of working on one project for an extended period, and when they do those tools are large and complex. So we probably don’t have every detail in our heads at any moment. If we could store all that information we wouldn’t need task tracking systems, you could just call us and tell us about a problem as we’d call you back a few hours/days/weeks later and say “fixed”.
Second, we’re terrible at finding mistakes in our own work. Like everyone else, we need editors. If I could see the problem you are reporting, I would probably have fixed it, or at least reported it to you so we could open a task to get it fixed later.
Third, we probably don’t spend as much time in the project documentation as you do. So if someone needs to track down the original design to check for a discrepancy between the design and what’s happening a developer is probably going to be much slower at this task than you are (or you will become soon).
Also remember your developer probably will not look at the problem today unless it’s mission critical to the client. So they need to be able to figure out three weeks from now what you were talking about. If it just says: “search is broken” and I run a search in two weeks and everything looks fine, you are going to need to tell me what’s broken about it (maybe a result is missing, maybe it’s formatted wrong, maybe it’s working perfectly but the client doesn’t like the results).
Even with all that context, I know it is intimidating for many new support or account team members to crack the code developers use when talking. We over explain this, using technical terms, and get annoyed too quickly when people don’t understand us. And we often forget that teaching by analogy is helpful.
My new colleague is a baker, and so as I was trying to help her understand what I needed to be helpful on tasks I switched to bread:
If I came to you and said “my bread didn’t work out, please tell me how to fix it” how would you start?
That helped her make the connection. Just saying my bread didn’t work out, doesn’t tell her enough to help me do it right next time. She’s going to have to ask several follow up questions before she can be helpful.
Did it taste wrong or look wrong?
What kind of bread was it?
Did you follow the instructions or do something different?
Are your ingredients fresh?
Did it rise enough?
Did you knead it enough?
Did you set the oven to the right temperature?
On the other hand if I come to her and say:
I tried to make sourdough oatmeal bread over the weekend. I followed the recipe closely, but my bread turned out really dense instead of having the bready texture I expected.
Now she knows there was a problem getting the bread to rise. So we can focus questions on the yeast and other details of getting air into bread. Yes, there are still several things that could have gone wrong, but now we know where to start.
Frequently new support staff are intimidated by all the technical things they don’t know. And too often developers brush aside new staff who don’t give them the information they need and just say things like “Oh I’ll figure it myself” instead of helping their colleagues learn. Part of the solution is to help people understand that the first set of questions aren’t actually technical. Baking isn’t the right analogy for everyone, but it helped in this case. And hopefully next time I’ll do better at getting to a better explanation quickly.
In December I gave a talk at the SCDUG meeting on Drupal 8 plugins. This is based on that talk with a few improvements and additions from things I’ve learned since.
Drupal 8 provides many great improvements, but one I’ve been finding to be the most exciting is the easy ability to create my own plugins. They are actually a bit addictive, and it’s easy to start seeing projects as an excuse to create a new plugin manager. At first it can take a little bit of effort to get your head around the process, but I got great details from Unraveling the Drupal 8 Plugin System from Drupalize.me. But the problem with those, and all the examples I could find, was they were either too deep (the drupalize.me article should be considered required reading, but the example is too abstract for most people) or too shallow (the drupal.org Plugin API examples currently lack context about why I would want to do this in practice).
So my goal is to straddle that gap.
What’s a plugin?
Plugins are a design pattern that let you extend a module or service. Drupal 8 has at least four plugin discovery systems:
Annotated ← I’m mostly talking about this one, its used for blocks, views, rules, Queue API, and more.
YAML ← These are used for menus, routes, and services.
Hook ← D7 carry over hook system, still used in many places.
Discovery Decorators ← Wrap around other plugin systems to replace/improve on the classic info alter hooks from previous Drupal versions.
Static ← These are used for test code, and I’m ignoring here.
Basic Commonly Used Plugins
As a Drupal 8 developer you probably use several plugins when building a site, particularly if there is any custom functionality required. When creating controllers you’ll need a route, and likely a menu item, which means you’ll use YAML files to define those aspects. For blocks, the queue api, or Rules you’ll create an annotated plugin. Theme functions are still commonly defined with hook_theme().
Why do I create new plugin?
Between core, and major contrib modules (like Rules and Search API), plugins options abound, but it’s not always obvious why you might want to create one for a more focused project. For large projects that may have a large number of related functions, poorly defined use cases, or use cases that are expected to expand over time Plugins provide three major advantages over other approaches:
Plugins make it easy to easily keep classes small and focused.
Plugins make it easy to extend a service.
Plugins allow one module to easily extend the function of another.
Actual Examples
Cyberwoven has a client who needed an internal training portal. They want to provide some basic gamification, particularly badges, and they wanted a more detailed tracking of user behavior than the core statistics module provides. The badges present a function that has many related, but different, use cases and is likely to grow over time. So I created a pluggable service that allows us to easily define a set of conditions for creating a new badge. Each plugin’s annotation lists the events it cares about, and when one of those events is fired the service runs the plugin’s test function. If the badge has been earned the plugin returns the information needed to generate that entity. All the event listening, entity generation, and error checking happens in the service, so each plugin is only focused on the details of the one badge. The event tracker is similar, with each plugin defining a filter for the major system events to determining what details should be recorded, and the service handling the logging of those details and reporting. As the client needs have evolved we’ve been able to add and modify the plugins to meet their needs.
The second place I’ve created a custom plugin system for was an internal project at Cyberwoven (it was actually the project I used to learn how to create custom plugins). Our testing server has always had a service to perform some basic operations on the server, like pulling repos via webhooks and similar tools to help developers. Setting up our development environments for D8 meant it was time for a new test server, and therefore new tools to manage it. From the start I wanted to create a tool that helped both developers and account managers. So I created a D8 site to manage the sites that provides various tools to perform task operations we all need (not only code handling, but also checking if security releases apply to any sites). All the various operations we want exposed through that site are created as plugins to our custom manager. Each task plugin is focused on just that one task. All the other various needed to track the sites, route requests to run a task, and render their responses are all handled in other places. It’s also now making it easy to add features that wrap around the plugins since the plugins all have a consistent interface (like adding new displays and running some tasks through cron).
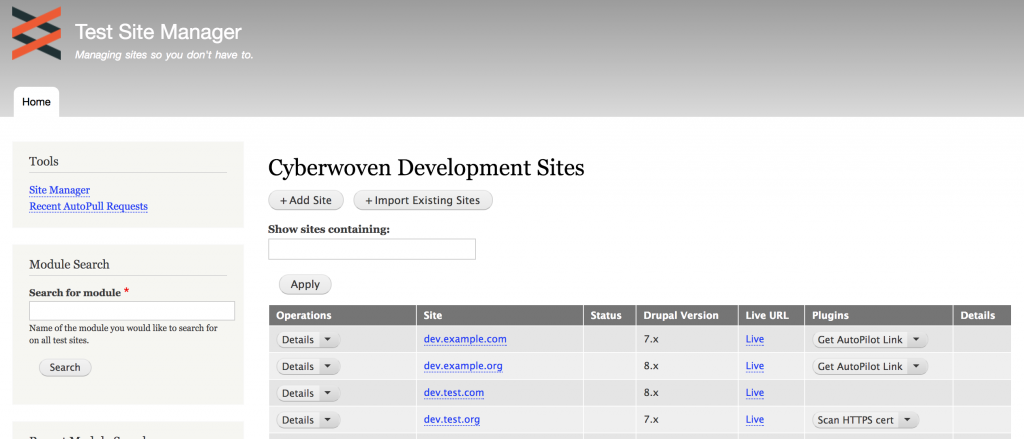
Introducing Site Manager
The listing page for the site manager tool. This runs on our server and can be run in developer’s sandboxes as well.
The main module defines an entity for each site, a couple displays (like the listing page displayed above), and the annotated plugin base so we can add new features easily. Plugins can be enabled and disabled on a site-by-site basis, and can be run from the plugins dropbutton.
Once we had the basics in place (like getting the git and drush status’s via simple plugins) we started to add more powerful features to turn the tool into a dashboard. We added the module search block you see on the left as a separate module that searches all sites for a specific Drupal module (nice when security updates are released). The search module also provides a plugin for each site that lists the modules for just that site.
The last site in the screen shot has a reference to scanning the HTTPS certificate for a specific site. This is another feature we added recently as this tool increasingly starts to serve as a dashboard. The HTTPS Scanner module again provides both a batch job to scan all sites, and a task plugin that scans just one.
As of this writing, all told there are nine working task plugins across four modules (there are a couple more underway as well). Tasks can also have their results displayed in a block when you look at the details for a site.
Building your own manager
Hopefully by now your convinced that it’s worth having your own plugin manager at least sometimes. So the next question is how to build them.
Elements of a custom plugin
Plugins have several parts, most of which are small and simple:
Annotation Plugin Definition
Plugin Manager Service
Plugin Interface
Plugin Base
Example Implementation
Controller (optional)
Annotation Plugin
The first step is to define the annotation for your plugin. This is a simple class that extends Drupal\Component\Annotation\Plugin to define the variables you want listed in the annotation comments of the plugin. This file goes in custom_module/src/Annotation, and as always the file name and class name match:
Plugin Manager Service
The plugin manager itself is a service, but the vast majority of its function comes from the parent classes. The convention is to place this file in custom_module/src/Plugin (as will the rest of the base definitions we’re about to provide). In this case we call it: TaskPluginManager.php.
The full version of this provides a few more improvements to this class (I overrode the getDefinitions() method to provide some filtering options to support disabling plugins), but those aren’t actually required for it to work well.
In short, this class just provides some general definitions to separate it from all the other annotated plugins.
And since the plugin manager is a service, we add it to our module’s service.yml file:
For this plugin I defined 4 critical public functions, three just provide basic information about a plugin, but fourth (run) will be the interesting one in a minute.
Plugin Base
Finally we’re getting to something interesting (or at least something that requires code). The plugin base is an abstract class which all the actual plugins will extend. This goes in custom_module/src/Plugin/TaskPluginBase.php.
The things worth taking notice of here are the fact that I inject several services into the base class, so I have them for each plugin: translation, main sitemanager module configuration, and a wrapper on Symfony’s process service to make running drush and git commands easier. The three informational functions are fully defined here, but the run function stays abstract since it’s the function that actually justifies creating a plugin at all.
In theory I could stop right there. I’ve created a plugin manager and defined all the things someone else needs to be able to use it. But there are two technically optional parts that are useful if you like to work and play well with others: an example implementation and a controller for use or testing purposes.
Example Implementation
We went through all the trouble to create the plugin manager, before you stop you should create at least one plugin to prove all the work we just did actually works.
This is a simple task to use drush to run cron for a site. The site entities know the location on the file system for Drupal root, and the simple task service handles the extra settings to control where the commands are run (and time outs and error trapping), so we can safely feed that to command and the location to get the response.
The method returns a render array, that can be used as part of a response.
Controller
The controller is truly 100% optional. There are two reasons you might want to create one: to actually run the plugin if that makes sense (it does for the site manager), and to provide for easy testing of a plugin.
For site manager I created the controller because I actually needed it to run the tasks from the dropbutton (its the link used by all the links on those buttons). But when I created the others for clients, I realized they can be very hard to test. They are buried inside several layers of complexity, making a test suite is a challenge to create correctly. And since are of the reason to use a plugin for a project with growing definitions, the test suite is often of limited use for rush additions. But by having a carefully built (and secured) controller and route, you can create an endpoint to use to test the plugin.
Because it’s optional, and well covered elsewhere (or heck just use Drupal console to generate it), I’m going to skip over most of the details of actually building the route, and linking that to the controller, and focus on the single function of running the task itself. To keep this short I’ve removed lots of extraneous details like security and error trapping – creating a tool like this isn’t for beginners so I’m assuming you know how to do those things.
The plugin manager service was injected into the controller (code not shown) so I just have it create an instance of the task requested. The controller calls the run function. If the task is successful the output (a render array) is used for the response, otherwise a simple message is send. This sends an AjaxResponse to work with Drupal’s standard JS handlers, but it could generate a full page just as easily.
Final thoughts
Being able to create your own plugins easily is really nice. In Drupal 7 custom plugins where generally considered an advanced developer task. The improvements in the abstraction (and the fact that true plugin support is now in core not pulled from ctools or other critical modules), means that while its still not a beginner task it is something all Drupal developers should be learning.
But remember you don’t always need or want the complexity of your own plugins. I’ve found the idea a bit addictive, and I get unreasonably excited when I find a place plugins are used or that it makes sense for me to create a new plugin type. For custom work you can almost always do the same thing using extra functions on a service, controller, or event listener, so this is a judgement call in the end.
Your documentation does not need to look like this.
Early in my career I spent a lot of time as the only technical person on project, and therefore believed that I didn’t need to document my work carefully since I was the only person who had to understand it later. It turned out that if a project was back burnered for a few months the details were pushed out of my mind by the details of eight other projects.
Any project that takes more than a couple hours to complete involves too many details for most people to remember for more than a few days. We often think about project documentation as something for other people – and it is – but that other person may be you in six months.
I learned to start keeping notes that I could go back to, those notes would turn into documentation that I could share with other people as the need developed. My solutions were typically ad-hoc: freeform word documents or wiki pages. For a while I had a boss who wanted every piece of documentation created by IT to fit a very predictable format and to be in a very specific system. It took two years for him to settle on the system, process, and format to use. By then I had a mountain of information in wiki pages that documented the organization’s online tools in detail, and no one else is IT had anything substantial. It was two more years before the documentation of other team members got to be as good as my ad-hoc wiki.
That’s not to say a rogue solution is best, but the solution that I used was better than his proposed setup for at least three years. That experience got me to think about what makes documentation useful.
Rules of thumb for good project documentation:
Write up the notes you’d want from others when coming into a project: think of this as the Golden Rule of documentation. Think about what you’d want to have if you were coming into the project six months from now. You’d want an outline of the purpose of the project and the solution used, and places they deviated from any standards your team normally uses. You’ve probably read documents that are explaining something technical to an expert that are hard for anyone else to understand – if I’m reading the documentation I want to become an expert, but I’m probably not one already.
Keep it easy to create and edit while working: if you have to stop what you’re doing and write your notes in a totally different environment that your day-to-day work you will not do it. Wikis, markdown files, and other similar informal solutions are more likely to actually get written and updated than any formal setup that you can’t update while doing your main work.
Document as you go: we all plan to go back and write documentation later and almost none of us do. When we do get back to it, we’ve forgotten half the details we need to make the notes useful to others. So admit you’re not going to get back to it and don’t plan to: write as you go and edit as you need.
Make sure you can come in in the middle: People skim project documentation, technical specifications, and any other large block of text. Make sure if someone has skipped the previous three sections they can either pick up where they left off, or give them directions to the parts the need to understand before continuing.
Track all contributions: Use a system that automatically tracks changes so you you can see contributions from others and fix mistakes. Tools like MediaWiki, WordPress, and Drupal do this internally. Markdown or text files in a code repository also have this trait. Avoid solutions like MS Word’s track changes that are meant for editing a final document not tracking revisions over time.
Don’t fear editing: follow the Wikipedia community’s encouragement to Be Bold. You should not fear making changes to the team’s documentation. You will be wrong in some of what you write, and you should fix any mistake you find – yours or someone else’s. Don’t get mad if someone makes a change that’s not quite right, revert the change or make a new edit and more forward.
There is always an audience: even if you are the only person on the project you have an audience of at least your future-self. Even if it feels like a waste in the moment having documentation will help down the road.
Remember even if you are working alone you’re on a team that includes at least yourself today and yourself in the future. That future version of you probably won’t remember everything you know right now, and will get very annoyed at you if you don’t record what they need to know. And if the rest of your team members aren’t just versions of yourself they may expressed their frustration more directly.
I have a degree in Computer Science, with a minor in Economics. But I earned that degree at Hamilton College, a traditional liberal arts college. That meant I was forced (now students there are just encouraged) to take classes in a variety of disciplines. I went to Hamilton in part because they offered degrees in Computer Science and History, and I was interested in both fields. In addition to the courses required by my major I took classes in history, religious studies, philosophy, art, and more. And I learned critical skills for work and life because I took those classes.
Making these mugs made me a better developer.
Ceramics and pottery taught me to be a craftsman, accept critical feedback, and admit failure. For all the courses I took in college, the time I spent in Ceramics and Pottery studio taught me more about how to be good at what I do than any other course work (including CS). Basic pottery is a craft that doesn’t allow you to save a piece once you’ve made mistakes. If you are making cylinders the walls aren’t straight throw it away and start again. My professor in those courses set very high standards and pushed us to meet them through brutally honest, but helpful, critiques. He taught me to appreciate honest feedback, and to be skeptical of my work before showing it others. In those courses we had to do good work, recognize our weaknesses, and hit deadlines.
History taught me to care about communicating. Between the courses I took, and dating (and eventually marrying) a history major (now professor) I came to understand how important it is to communicate well in speech and in writing. I started this blog in part because I wanted to make sure I was spending more time writing to help maintain those skills. I frequently find myself in meetings having to explain highly technical issues to non-technical clients and colleagues. Knowing how to adjust to my audience, without insulting their intelligence, is a critical part of my day to day work.
Religious Studies and Philosophy taught me to make a well reasoned argument and express the ethics of my position. Religious Studies and Philosophy both require you to make arguments based primarily on the strengths of your ideas – you can’t research your way out of a bad concept. If you cannot assemble a well reasoned argument you leave yourself open to easy counter attacks. When you work at a nonprofit you often are building your ideas and your explanations from a mix of the facts of the issue, your worldview, and the assumptions you are forced to make because no one has all the information they really need.
Economics taught me how to view the world through the lens of money and trade. While I don’t think it’s the only, or even best, way to view the world it is a very important worldview that dominates the news and political spaces. Understanding the strengths and weaknesses of economics as a field helps me think about plans put forward by various politicians. It also helps me think about how the companies I work for function, and helps make sure internal systems and plans I propose have a strong business case to support them (and because I learned to throw things away in ceramics I also know that when the case is bad to stop and try something different).
The most important skill I have is the ability to learn new skills. Since I graduated from college the technology I work with every day has changed several times. I’ve had to learn tools, techniques, and strategies that didn’t exist when I was in college. And my career has evolved through multiple employers, disciplines, and areas of expertise.
This week we get a letter from Atlantic Broadband, our ISP, addressed to “Aaron & Eliza Crosman Geor”. My wife has never gone by Eliza and her last name is not “Geor”.
It’s been this way since we signed up with them, when we ask them to fix it they acknowledge that they cannot because their database cannot correctly handle couples with different last names who both want to appear on the account. Apparently it is the position of Atlantic Broadband that in 2016 it is reasonable to tell a woman she cannot be addressed by her legal name because it would be expensive for them to fix their database, and therefore she must be misaddressed or left out entirely.
I consider this unacceptable from old companies, but Atlantic BB was founded in 2004 – there are probably articles about not making assumptions about people’s names that are older than their company.
Folks, it is 2016, when companies insult people and then blame their databases it is because they do not consider all their customers worthy of equal respect.
So let’s get a few basics out of the way:
Software reflects the biases of the people who write it and buy it.
If your database tells someone their name is invalid your database is not neutral. Just because you don’t get the push-back that Facebook sees when they mess this up does not mean what you’re doing is okay.
If your database assumes my household follows 1950s social norms, the company that uses it considers 1950s social norms acceptable in 2016 – and there are probably a few of those they don’t want to defend (I hope).
When an email, phone rep, or letter calls me by my wife’s last name or her by mine, in both cases they are assuming she has my last name not that I have hers. This is a sexist assumption that the company has chosen to allow.
Of course Atlantic isn’t the only company that does this: Verizon calls me Elizabeth in email a couple times a week because she must be primary on that account (one person must lead the family plan), and Nationwide Insurance had to hack their data fields for years so my wife could appear on our car insurance card (as required by law) every time we moved because their web interface no longer allowed the needed changes. The same bad design assumptions can be insulting for other reasons such as ethnic discrimination. My grandmother was mis-addressed by just about everyone until she died because in the 1960s the Social Security Administration could not handle having an ‘ in her name, and no one was willing to fix it in the 50 years that followed SSA’s uninvited edit to her (and many other people’s) name.
In all these cases representatives all say something to the effect of “our computers cannot handle it.” And that of course is simply not true. Your systems may not be setup to handle real people, but that’s because you don’t believe they should be.
Let’s check Atlantic Broadband’s beliefs about their customers based on how they address us (I’m sure there are some additional assumptions not reflected here but these are the ones they managed to encode in one line in this letter):
They assume they are addressing one primary account holder: I happen to know from my interactions with them that they list my first name as: “Aaron & Eliza”, and my last name as “Crosman Geor”. Plenty of households have more than one, or even two, adults who expect equal treatment in their home. Our bank and mortgage company know we are both responsible adults why is this so hard for an ISP (or insurance company, or cell provider, credit card, etc)?
They assume my first name isn’t very long: They allowed 13 characters, but 4 more is too many. I went to high school with a kid who broke their database by exceeding the 26 character limit it had (they didn’t ask the kid to change his name, the school database admin fixed the database), but Atlantic can barely handle half that.
They assume my last name isn’t very long: Only 12 characters were used and they stopped in a strange place. I know many people with last name longer than that: frequently people who have hyphenated last names blow past 12. Also the kid with a 26 character first name – his surname was longer.
They assume my middle name isn’t an important part of my name: If they had a middle name field, they could squeeze a few more letters in and make this read more sensibly. But they only consider first and last names important. Plenty of people have three names – or more – they like to have included on letters.
They assume it is okay to mis-address me and my wife: The name listed is just plain wrong, but they believe it’s okay to keep using this greeting. They assume this even after they have been told it’s not, and even after we’ve reduced service with them (if another ISP provided service to my house I’d probably cut it entirely although mostly for other reasons). They believe misaddressed advertisements will convince me I need a landline or cable package again.
Now I’ll be fair for just a minute and note something they got right: they allow & and spaces in a name so Little Bobby Tablesmight be able to be a customer without causing a crisis (partially because his name is too long for them to fit a valid SQL command into the field).
Frequently you’ll hear customers blame themselves because their names are too long or they have done something outside the “norm”. Let’s be clear: this is the fault of the people who write and buy the software. Software development is entirely too dominated by men, as is the leadership of large companies. When a company lacks diversity in key roles you see that reflected in the systems built to support the work. Atlantic’s leadership’s priorities and views are reflected in how their customers are addressed because they did not demand the developers correct their sexist assumptions.
These problems are too common for us to be able to refuse to do business when it comes up. I will say that when we switched our insurance to State Farm they did not have any trouble understanding that we had different last names and their systems accommodated that by default.
If you do business with a company that makes these (or other similar mistakes) I think it’s totally reasonable to remind them every time you reasonable can that it’s offensive. Explain that they company is denying you, your loved ones, and/or your friends a major marker of their identity. Remind them they are not neutral.
If you write data systems for a living: check the assumptions you’re building into your code. Don’t blame the technology because you used the wrong character set or trimmed the field too short: disk is cheap, UTF-8 has been standard for 15+ years, and processors are fast. If the database or report layout doesn’t work because someone’s name is too long the flaw is not the name.
We all make mistakes and bad assumptions sometimes, but that does not make it okay to deny people basic respect. When we make a bad assumption, that’s a bug, and good developers are obligated to fix it. Good companies are obligated to prevent it from happening in the first place.
As part of my effort not to repeat mistakes I have tried to build a habit in my professional – and personal – life to look for ways to be better at what I do. I recently rediscovered how much you can learn when you try doing something you know well backwards: I drove on the left side of the road.
This is the Holden Barina we rented while in New Zealand, a brand of car I’d never heard of before this trip. It was a good car for the mountain driving even if the wipers and lights controls were reversed from cars at home.
By driving on the left I discovered how many basic driving habits I have that are built around driving on the right. The clearest being that the whole time I was in New Zealand I never knew if anyone was behind me, and the whole time I couldn’t figure out why. The mirrors on the car worked just fine, but it turned out I wasn’t looking at them. Driving home from the airport after we returned to the US I realized that every few seconds my eyes jump to the upper right of my vision to check the mirror. In New Zealand I spent the whole time glancing at the post between the windshield and the driver’s side window (which had seemed massive to me while I was there) instead of the mirror. It made me conscious of my driving habits in a way I haven’t been in years, and as a consequence, I think it’s made me a better driver. I’m thinking about little details again; I’ve been more aware of where I am on the road and what I’m doing to keep track of the other cars around me.
My wife drove this section while I got to take some pictures. She got to learn to drive on the left on winding mountain roads – we don’t recommend that approach.
A few years ago I was watching videos from the MIT Algorithms course to refresh some of my basics, and because I wanted to know what had been added in the decade since I’d taken that class at Hamilton. During the review of QuickSort the professor mentioned that it wasn’t originally a divide-and-conqueror process, but a loop based approach meant to work on a fixed length array (so you could use a fixed block of memory). And as I recall he suggests that the students should work out the loop based version. So riding on the train home from work I pieced it together, and found that it’s an elegant process. It’s not something I ever expect to have cause to implement, but it did help me improve my thinking about when to use recursive functions vs when to use a loop, and helped me think about when to use recursion, loops, and other tools for processing everything in a list. There was a session by John Kary at DrupalCon this year on rethinking loops that pushed me again to revise some of how I made those decisions. Again his talk took the reverse view of much of my previous thinking and was therefore very much worth my time.
If you’re feeling like you are in a good groove on something, try doing it backwards and see what you discover.