This week I was working on a Drupal 8 project that includes a page that uses Drupal as a simple proxy to convert a weak XML API into a simple JSON response. To ensure good performance I wanted to ensure I had cached JSON responses.
When I first built the site I hadn’t yet gotten my head around Drupal 8 caching, and so the JSON responses weren’t cached and therefore the page was slow. After some issues with the site caused me to have to look at this part of the project again I decided it was time to try to do something about this.
Drupal 8’s use of Symfony means we have great tools for simple tasks like providing JSON responses. Originally in the controller all I had to do was provide the JsonResponse class an array of data and it would handle the rest:
That’s all well and good if you don’t want your response to ever be cached, but Drupal provides a CacheableJsonResponse class that links up to the rest of the Drupal 8 caching engine to provide much better performance than a stand Symfony JsonResponse. But it turns out the docs kinda suck for explaining how to use it. After a great deal of digging I found this Question on StackExchange which gave me what I needed.
Edit: You must enable the Internal Dynamic Page Cache module to get CacheableJsonResponse to work correctly. Thank you for the correction.
One of the things that the Drupal community has learned in the last few weeks is that our current governance structures aren’t working in several ways. Having spent a lot of time at DrupalCon talking about these issues I figured I share a few initial thoughts for those working on our new processes.
This isn’t the first time I’ve been part of a community that was changing how it organizes itself. In my religious life I am a Quaker, and for a long time I was a member of Philadelphia Yearly Meeting which is the regional organizing body for Quakers in the greater Philadelphia area. And I served for a time on several of their leadership committees. I’ve seen that 300+ year old group pass through at least three different governance structures, and while many of the fundamentals are the same, the details that matter to people also change a lot.
My great aunt put it into perspective during one of the long discussions about change. When my wife asked her for her opinion about a then pending proposal she responded that it didn’t matter much to her as long as it worked for those willing to take leadership roles at the moment.
So as the Drupal community grows through a process to change our leadership structure here are the things I think it is important for all of us to remember.
It will not be perfect. We’re human, we will make mistakes, that’s okay.
It will change again. I don’t know when or why, but whatever we do will serve us for a time, and then we’ll replace it again.
Most of the community won’t care most of the time. Most of the time, most of us don’t notice what Dries, the Drupal Association, Community Working Group, and all the other groups that provide vision and leadership are doing.
I think we can all agree my first point is a given. I mention it mostly because some of us will find fault in anything done going forward. We should remember the people doing this work are doing the best they can and give them support to do it well.
On the plus side, whatever mistakes we make will be temporary because Drupal and its community will outlive whatever we create this time. We’ll outgrow it, get annoyed with the flaws, or just plain decide to change it again. Whatever we build needs to be designed to be changed, improved, and replaced in the future. Think about it like the clauses in the U.S. constitution designed to allow amends to the constitution itself.
Finally, we should remember that community and project governance is insider baseball. Understanding how and why we have the leadership we do is like watching a pitching duel on a rainy day, most baseball fans don’t enjoy those kinds of games. Most of our community wants to use Drupal and they don’t want to have to think about how DrupalCon, Drupal.org, and other other spaces and events are managed. That will not prevent them from complaining next time there are problems, but it is a fact of life those who do care should acknowledge.
Our community is stronger than we have been giving it credit for in the last few weeks. We need to be patient and kind with each other, and we’ll get through this and the divisions that will come in the future.
I’m using this post as a place to store and share “notes” from DrupalCon Baltimore. The part of conference notes I tend to find most useful are links and stray ideas I get talking with people. I don’t tend to take detailed notes anymore since I rarely if ever go back to those, although on rare occasions I do re-watch a session if I found it particularly useful.
Basically this is a dump of links, pictures from various things, and a few stray thoughts. I’ll edit as the week progresses and probably add more thoughts and ideas.
poser.pugx.org provides badges on packagist pages.
https://scrutinizer-ci.com/ “Sometimes any static analysis tools will give you answers you don’t like so just ignore it.”
https://www.versioneye.com/ uses the licenses from composer.json to check for both out of date and for compatible licenses. Not terribly useful internally, but user for open projects since you can link a badge to the result. Alternative `composer licenses` which is actually smarter.
Main Take away: Commerce in D8 is much closer to ready than I thought, mainly cause like Drupal core much more functionality was moved from supporting modules into Commerce core.
Main Take Aways: It seems to be working, and we’re confident enough about the current plan that I think it’s a bit more real than it’s been in the past. And there are ways to track (engage in) what’s being considered for new features.
For Drupal 7, I have a pattern to help simplify creating and managing custom blocks for a site. Since the standard hook_block_info() and really hook_block_view() implementations tend to get messy and junked up with markup in the code. My solution was the use the block delta key from the block info array as a helper function name called from the hook_block_view(), and a theme function in hook_theme() to make sure I could easily create a template for each block. I’m not going into detail about it since was hardly original and I’ve seen several variations from other developers.
When I started to work on Drupal 8 I wanted to develop a similar pattern to help create simple conventions for integration with front end work on a project. While the new plugin system helps avoid the ugliness of old hook_block_view() implementations, how to create a twig file for your custom block isn’t obvious and doesn’t impose a naming convention. Worse, I’ve seen lots of example code with blocks that return render arrays of type markup meaning they have HTML in strings in PHP.
Most projects involve a collection of nearly static blocks that provide basic information like the copyright information, a disclaimer text, a link to the firm that built the site, decorative flourishes, and other similar elements that don’t benefit from being managed as content. After a couple experiments I’ve come up with a solution that works pretty well:
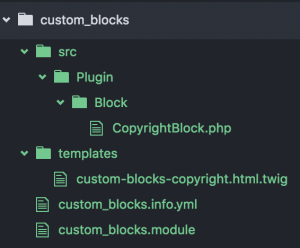
Outline of the custom blocks pattern.
Create a module for simple blocks (although I use the rest of the pattern anytime I’m creating a custom block).
Create the block class for each block within the module at src/Plugin/Block/CopyrightBlock.php.
Create a theme function for each block in the main .module file.
Create a twig file to implement the theme function within the module at templates/custom-blocks-copyright.html.twig.
The for a copyright block the class itself is simple. We implement the variables we want rendered by the block, and set the cache to expire at midnight (one of the places a timed cache makes more sense that cache tags):
With the block created, we need to define the custom_blocks_copyright theme function we included in the block using hook_theme() from within the dot module file. Remember any custom variables you used in the block class need to also be defined here (in this case attributes and year):
Finally, create the twig file to provide the actual markup.
In December I gave a talk at the SCDUG meeting on Drupal 8 plugins. This is based on that talk with a few improvements and additions from things I’ve learned since.
Drupal 8 provides many great improvements, but one I’ve been finding to be the most exciting is the easy ability to create my own plugins. They are actually a bit addictive, and it’s easy to start seeing projects as an excuse to create a new plugin manager. At first it can take a little bit of effort to get your head around the process, but I got great details from Unraveling the Drupal 8 Plugin System from Drupalize.me. But the problem with those, and all the examples I could find, was they were either too deep (the drupalize.me article should be considered required reading, but the example is too abstract for most people) or too shallow (the drupal.org Plugin API examples currently lack context about why I would want to do this in practice).
So my goal is to straddle that gap.
What’s a plugin?
Plugins are a design pattern that let you extend a module or service. Drupal 8 has at least four plugin discovery systems:
Annotated ← I’m mostly talking about this one, its used for blocks, views, rules, Queue API, and more.
YAML ← These are used for menus, routes, and services.
Hook ← D7 carry over hook system, still used in many places.
Discovery Decorators ← Wrap around other plugin systems to replace/improve on the classic info alter hooks from previous Drupal versions.
Static ← These are used for test code, and I’m ignoring here.
Basic Commonly Used Plugins
As a Drupal 8 developer you probably use several plugins when building a site, particularly if there is any custom functionality required. When creating controllers you’ll need a route, and likely a menu item, which means you’ll use YAML files to define those aspects. For blocks, the queue api, or Rules you’ll create an annotated plugin. Theme functions are still commonly defined with hook_theme().
Why do I create new plugin?
Between core, and major contrib modules (like Rules and Search API), plugins options abound, but it’s not always obvious why you might want to create one for a more focused project. For large projects that may have a large number of related functions, poorly defined use cases, or use cases that are expected to expand over time Plugins provide three major advantages over other approaches:
Plugins make it easy to easily keep classes small and focused.
Plugins make it easy to extend a service.
Plugins allow one module to easily extend the function of another.
Actual Examples
Cyberwoven has a client who needed an internal training portal. They want to provide some basic gamification, particularly badges, and they wanted a more detailed tracking of user behavior than the core statistics module provides. The badges present a function that has many related, but different, use cases and is likely to grow over time. So I created a pluggable service that allows us to easily define a set of conditions for creating a new badge. Each plugin’s annotation lists the events it cares about, and when one of those events is fired the service runs the plugin’s test function. If the badge has been earned the plugin returns the information needed to generate that entity. All the event listening, entity generation, and error checking happens in the service, so each plugin is only focused on the details of the one badge. The event tracker is similar, with each plugin defining a filter for the major system events to determining what details should be recorded, and the service handling the logging of those details and reporting. As the client needs have evolved we’ve been able to add and modify the plugins to meet their needs.
The second place I’ve created a custom plugin system for was an internal project at Cyberwoven (it was actually the project I used to learn how to create custom plugins). Our testing server has always had a service to perform some basic operations on the server, like pulling repos via webhooks and similar tools to help developers. Setting up our development environments for D8 meant it was time for a new test server, and therefore new tools to manage it. From the start I wanted to create a tool that helped both developers and account managers. So I created a D8 site to manage the sites that provides various tools to perform task operations we all need (not only code handling, but also checking if security releases apply to any sites). All the various operations we want exposed through that site are created as plugins to our custom manager. Each task plugin is focused on just that one task. All the other various needed to track the sites, route requests to run a task, and render their responses are all handled in other places. It’s also now making it easy to add features that wrap around the plugins since the plugins all have a consistent interface (like adding new displays and running some tasks through cron).
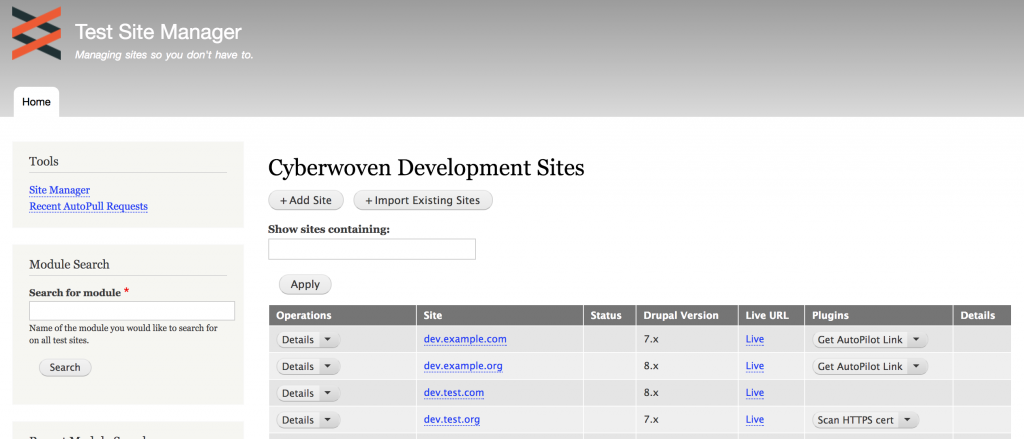
Introducing Site Manager
The listing page for the site manager tool. This runs on our server and can be run in developer’s sandboxes as well.
The main module defines an entity for each site, a couple displays (like the listing page displayed above), and the annotated plugin base so we can add new features easily. Plugins can be enabled and disabled on a site-by-site basis, and can be run from the plugins dropbutton.
Once we had the basics in place (like getting the git and drush status’s via simple plugins) we started to add more powerful features to turn the tool into a dashboard. We added the module search block you see on the left as a separate module that searches all sites for a specific Drupal module (nice when security updates are released). The search module also provides a plugin for each site that lists the modules for just that site.
The last site in the screen shot has a reference to scanning the HTTPS certificate for a specific site. This is another feature we added recently as this tool increasingly starts to serve as a dashboard. The HTTPS Scanner module again provides both a batch job to scan all sites, and a task plugin that scans just one.
As of this writing, all told there are nine working task plugins across four modules (there are a couple more underway as well). Tasks can also have their results displayed in a block when you look at the details for a site.
Building your own manager
Hopefully by now your convinced that it’s worth having your own plugin manager at least sometimes. So the next question is how to build them.
Elements of a custom plugin
Plugins have several parts, most of which are small and simple:
Annotation Plugin Definition
Plugin Manager Service
Plugin Interface
Plugin Base
Example Implementation
Controller (optional)
Annotation Plugin
The first step is to define the annotation for your plugin. This is a simple class that extends Drupal\Component\Annotation\Plugin to define the variables you want listed in the annotation comments of the plugin. This file goes in custom_module/src/Annotation, and as always the file name and class name match:
Plugin Manager Service
The plugin manager itself is a service, but the vast majority of its function comes from the parent classes. The convention is to place this file in custom_module/src/Plugin (as will the rest of the base definitions we’re about to provide). In this case we call it: TaskPluginManager.php.
The full version of this provides a few more improvements to this class (I overrode the getDefinitions() method to provide some filtering options to support disabling plugins), but those aren’t actually required for it to work well.
In short, this class just provides some general definitions to separate it from all the other annotated plugins.
And since the plugin manager is a service, we add it to our module’s service.yml file:
For this plugin I defined 4 critical public functions, three just provide basic information about a plugin, but fourth (run) will be the interesting one in a minute.
Plugin Base
Finally we’re getting to something interesting (or at least something that requires code). The plugin base is an abstract class which all the actual plugins will extend. This goes in custom_module/src/Plugin/TaskPluginBase.php.
The things worth taking notice of here are the fact that I inject several services into the base class, so I have them for each plugin: translation, main sitemanager module configuration, and a wrapper on Symfony’s process service to make running drush and git commands easier. The three informational functions are fully defined here, but the run function stays abstract since it’s the function that actually justifies creating a plugin at all.
In theory I could stop right there. I’ve created a plugin manager and defined all the things someone else needs to be able to use it. But there are two technically optional parts that are useful if you like to work and play well with others: an example implementation and a controller for use or testing purposes.
Example Implementation
We went through all the trouble to create the plugin manager, before you stop you should create at least one plugin to prove all the work we just did actually works.
This is a simple task to use drush to run cron for a site. The site entities know the location on the file system for Drupal root, and the simple task service handles the extra settings to control where the commands are run (and time outs and error trapping), so we can safely feed that to command and the location to get the response.
The method returns a render array, that can be used as part of a response.
Controller
The controller is truly 100% optional. There are two reasons you might want to create one: to actually run the plugin if that makes sense (it does for the site manager), and to provide for easy testing of a plugin.
For site manager I created the controller because I actually needed it to run the tasks from the dropbutton (its the link used by all the links on those buttons). But when I created the others for clients, I realized they can be very hard to test. They are buried inside several layers of complexity, making a test suite is a challenge to create correctly. And since are of the reason to use a plugin for a project with growing definitions, the test suite is often of limited use for rush additions. But by having a carefully built (and secured) controller and route, you can create an endpoint to use to test the plugin.
Because it’s optional, and well covered elsewhere (or heck just use Drupal console to generate it), I’m going to skip over most of the details of actually building the route, and linking that to the controller, and focus on the single function of running the task itself. To keep this short I’ve removed lots of extraneous details like security and error trapping – creating a tool like this isn’t for beginners so I’m assuming you know how to do those things.
The plugin manager service was injected into the controller (code not shown) so I just have it create an instance of the task requested. The controller calls the run function. If the task is successful the output (a render array) is used for the response, otherwise a simple message is send. This sends an AjaxResponse to work with Drupal’s standard JS handlers, but it could generate a full page just as easily.
Final thoughts
Being able to create your own plugins easily is really nice. In Drupal 7 custom plugins where generally considered an advanced developer task. The improvements in the abstraction (and the fact that true plugin support is now in core not pulled from ctools or other critical modules), means that while its still not a beginner task it is something all Drupal developers should be learning.
But remember you don’t always need or want the complexity of your own plugins. I’ve found the idea a bit addictive, and I get unreasonably excited when I find a place plugins are used or that it makes sense for me to create a new plugin type. For custom work you can almost always do the same thing using extra functions on a service, controller, or event listener, so this is a judgement call in the end.
If you support any web site long enough you will suffer a break in. If you support lots of web sites you will suffer them more often than you’ll want to admit in public. A few weeks ago my number came up again in the attack lottery when we discovered a client’s web site was being used as a proxy and redirect to a fake shoe site.
It wasn’t the first time I’d suffered a break in, and unfortunately I don’t expect it to be the last. My last experience with a major break in was shortly after Drupalgeddon (I patched all the clients I was supporting before they were breached but had to clean up sites that weren’t patched by other vendors), and the attackers had learned a few new tricks in the meantime.
If you are responding to a break in on a Drupal site there are directions on drupal.org to help guide you through an attack response, but I thought it might be helpful to talk through a version of what response can look like in practice. I think it’s also useful for us all to admit our weaknesses from time to time to help us all make sure we’re making new mistakes.
Overview
At the outset I’m going to admit we never found the initial source of the attack, what we did find were the tools they placed after the break in. The most likely cause was poor server patching practices by the client’s host, but there were also some Drupal security patches that had been slow to be get installed as well. During the attack I worked with members of the Drupal Security team (particularly Greg Knaddison who generously provided feedback on this article as well – of course any remaining mistakes are mine), who were helpful in giving me suggestions and who were clearly interested in helping us make sure we resolved the problem.
The site was being used as part of a scam advertising network. The attacker was leveraging the reputation of the site to create records in search engine indexes that were redirects to a fake shoe sales site. There were also a number of tools placed on the server that gave them full access to the Drupal database and the ability to run arbitrary PHP scripts. And it was clear by the end they had placed additional backdoors we never found – they may have had full control over the OS as well.
How we found out
Google told us.
We got an alert from Google reporting SPAM content on the site. At first we couldn’t find the content they were talking about, which unfortunately slowed our escalating our response, because it was only directly available to search engines. The junior developer who was initially assigned to review the message from Google eventually figured out how to find the listing on Google (a Google site search for Nikes and some hash codes the attacker was using), but couldn’t figure out how out it got there, and escalated the task to me.
Once I saw what she’d figured out my stomach sank. At first I was still hoping there might be some other explanation, or some simple matter of a single user account getting exploited, but that seemed unlikely (since we couldn’t find the content on the server) and I quickly knew it was going to be a mess.
Initial Response
The first thing I did was make sure we had a copy of the exploited site: code, files, and database. I would have rolled the site back to a recent backup, but our five-day rolling database snapshots were not enough to get back to before the attack began. We spun up new virtual machines for myself and another senior developer to start reviewing copies in environments isolated from other work.
Since the URLs we had for testing were a fairly unique pattern we started to Google those – and we got lots of hits. As soon as we knew the problem was larger than our site, we opened an issue with the Drupal security team and started to feed them all the information we had gathered. While their practice is not to get involved in resolving attacks directly (their role is to ensure the security of Drupal core and contributed modules), they were supportive and helpful in suggesting places to look for problems and resolution strategies.
Attacks we found
By the time I was alerted to the problem there were already several malicious tools installed, some of which I’d seen versions of before, and some were new to me – all were designed to be hidden from sight through some simple but effective obfuscation. Over the course of the next couple of days I found several backdoors manually, wrote tools to help me find more, and played entirely too much whack-a-mole (more on that in a bit).
There were two main categories of attack I was chasing: PHP scripts scattered around the public files directory, and records added to Drupal’s database tables.
Database table exploits
If you dealt with sites in the aftermath of Drupalgeddon, or other hacked Drupal sites, you have probably seen what happens when an attacker inserts PHP into carefully targeted parts of a Drupal database. In the ones I’d seen before attackers replaced the callback functions in Drupal’s menu_router table with PHP of their own. In this case the attacker used the Block module’s ability to use PHP to place a block to provide themselves a way to execute arbitrary PHP by sending a post request to the server. They leveraged the fact that the main system block is always available and therefore is a reliable place to insert a backdoor. By posting a form with a specific form element they were able to execute arbitrary PHP and therefore use that to place additional malicious code.
The attacker also leveraged Drupal’s system table to get more complex attack code loaded. They created a record for a file to be loaded as a module and then uploaded that file to the site’s files directory where they were guaranteed Drupal had write access.
filename: sites/default/files/styles/medium/public/57h3d21.jpg
name:overly
type: module
owner:
status:1
bootstrap: 0
schema_version:0
weight: 0
info: a:11:{s:4:"name";s:6:"overly";s:11:"description";s:58:"Displays the Drupal administration interface in an overly.";s:7:"package";s:4:"Core";s:7:"version";s:4:"7.32";s:4:"core";s:3:"7.x";s:7:"project";s:6:"drupal";s:9:"datestamp";s:10:"1413387510";s:12:"dependencies";a:0:{}s:3:"php";s:5:"5.2.4";s:5:"files";a:0:{}s:9:"bootstrap";i:0;}
This was the script doing the redirects and filtering traffic so that pages only appeared to search engines. Usually these records have filenames that are .module, .php, or .inc files, but in this case it was a .jpg file named to be similarly to actual files on the site to make it hard to spot.
The content of that file was a PHP script not an image. The script did several things, and was the main tool the attacker was actively using during the time we were trying to stop them. It served as a simple proxy of content that they would present to the search engines, and redirect those same pages to the scam site for anyone else. It also provided code to make sure the content of user login forms was sent to the attacker, and a backup backdoor incase some of their others were lost.
We actually had to remove this particular attack more than once (always using the misspelled “overly” module) and each time it came back with a new file, and each time using a different but similar disguise to try to make their code blend in with legitimate files.
.htaccess files in public files
The other trick that was new to me (and a more aggressive stance by Drupal core on this approach is being discussed) was to take advantage of the .htaccess patterns in Apache to re-enable PHP execution within the public files directory. Drupal’s default .htaccess file disables PHP at the root of the public files directory and in theory all subdirectories, but that can simply be undone by a malicious .htaccess file (unless you block it in Apache’s main configuration – which in my opinion defeats the purpose of using .htaccess).
The attacker had placed a number of basic PHP-based exploits on the server using this technique to allow them to run the scripts. The tools themselves were not Drupal-specific, and likely the .htaccess file would work just as well on a number of other PHP-based CMS platforms.
Since the files directory gets deep and complicated there is no reasonable way to scan the whole thing by hand: particularly since several of the files were using inaccurate file extensions (like .jpg or no extension at all) and file names meant to blend into the background. So in addition to checking for any .htaccess files below the files directory root, I wrote a simple Python script to scan a directory for anything that includes the string <?php:
How we fixed it
We immediately made sure all code on the site was up-to-date, and I removed every exploit I could find. And for a couple days I played whack-a-mole with the attacker. Every day I would remove a series of exploits, disable their ability to redirect users to their scam, and every night they would break back in through a backdoor I’d failed to find.
The final solution was to replace the server, deploy a version of the code known to be good, and deploying copies of the database and files that have been scanned for any PHP in places it shouldn’t be – which involved a combination of the scanner above and hand checking every place the database stores PHP, not a fast process.
What we will do better next time
Part of any security event of this nature needs to be a full review of your internal processes and controls to make sure you reduce your risk and improve your response the next time something occurs (because unfortunately there will be a next time for all of us).
One of our first areas of improvement is a shared understanding that it’s more important to resolve the attack than determine the cause. This goes against the question that developers are constantly asked during and after an attack: “How did this happen?” While you need to know something about what happened, in the end it’s more important to make it stop. I still don’t know what happened that started the attack, I know I stopped it by blocking every attack vector I could think of and replacing every part of the stack with a version known to be fully up-to-date. It would have been faster and cheaper if I’d just started there: yes there is a risk I would have missed some of the code in the database if I hadn’t taken the time to review what I was finding, but frankly I doubt that risk is has high as the risk that new exploits will appear while I’m working to understand the previous one.
Beyond that basic shift in approach we developed a three part list of improvements:
Things we needed to improve right away.
Things we needed to improve soon.
Things that should be part of ongoing improvement.
The highest priority items were coming up with better internal process for initial response, and making sure we are deploying all security updates in a timely but still careful manner, including monitoring our hosting partners to ensure servers stay up-to-date as well. These are basics that are easy to let slip over time – particularly monitoring that your partners are doing their job correctly.
The second category of fixes is filled with workflow and procedure improvements. We were already were in the process of improving our code handling (migrating from SVN to Git, better production monitoring, more internal code review, etc), and we accelerated our plans to complete that work. This category also includes a complete review of our existing backup procedures to make sure they provide the level of coverage our clients need.
The final category of longer term adjustments includes tasks that include ensuring all developers are given (and expected to take) professional development opportunities around security best practices, doing more internal sharing about emerging ideas and trends, and encouraging more community engagement so we are better able to leverage the community resources in a crisis.
Last week Cyberwoven hosted the local SC DUG. To encourage people to come when we hold these events in Columbia I’ve blatantly started to bribe people with baked goods: I give the presenter a choice of Cookies, Cake, or Pie – everyone picks cookies (unless I swap in Brownies instead of cookies then they pick brownies), no one asks for pie or cake. This month Will gave a talk about Docker and asked for cake! Since I was excited to finally have someone actually ask for something interesting I decided to do something Drupal themed: I made Drupal Cake.
Turns out if you go Googling for Drupal cake you get ideas for how to make a yellow or white cake and decorate it with a Drupal logo. There are some notable counterexamples, but I wanted something with more Drupal baked in.
So I made a Chocolate Blue Velvet Cake with a Drupal logo in blueberries.
This recipe is derived from All Cake’s Considered’s Dark-Chocolate Red Velvet Cake (if you’re an NPR-nerd you should buy a copy but it is also available in its entirety from the Internet Archive – I assume legally).
Of course hers is red, and I wanted blue. But since my actual inspiration came from people providing recipes (mostly bad ones) for baby shower cakes getting suggestions about how much food coloring to use wasn’t hard. So a little marriage of ideas and you have Chocolate Blue Velvet Drupal Cake.
Ingredients
Cake:
2 Sticks of unsalted butter at room temperature
1 ¼ cups sugar
1 ¼ cups brown sugar
6 large eggs at room temperature
2 teaspoons vanilla extract
3 cups all-purpose flour
½ teaspoon baking soda
¼ cup Dutch process cocoa
½ teaspoon baking powder
1 cup sour cream
1 ounce Blue icing coloring (my version used food coloring but didn’t have quite the color I wanted. Icing coloring is usually stronger so this should get you closer).
Icing:
½ cup (1 stick) unsalted butter at room temperature
2 8-ounce packages cream cheese at room temperature
32-ounces of confectioners’ (powdered) sugar.
1 teaspoon vanilla extract
1 package of fresh Blueberries
Instructions
Preheat the oven to 325°F
Cream the butter and then gradually add the sugars beating well as you go.
Add the eggs one at a time, beating well between each.
Add the vanilla extract and beat for another couple of minutes.
In a separate bowl combine and lightly mix the dry ingredients.
Alternate adding roughly ⅓ of the dry mixture followed by ⅓ of the sour cream, beating well after each addition, until all of both are fully incorporated.
Add the coloring, and continue to beat well. After a minute stop the mixer and using a spatula to get any unevenly dyed batter off the sides and bottom, and then beat until the color is even.
Pour the batter into a pair of well greased 8 or 9-inch round cake pans, and place them in the oven so they have as similar of conditions as possible.
Bake for 45 minutes or until the cake tests done.
Cool the layers in their pans for 10 minutes and then remove from their pans carefully. Let them cool to room temperature.
Frosting:
Cream the butter and the cream cheese at medium speed.
Gradually add the confectioners sugar. Continue beating until the it is light and fluffy.
To Assemble the Cake:
Wait until the cake is fully cooled to room temperature. You need one to be flat (to form the bottom layer) so if domes formed on both cakes, use a long knife to cut the top of one layer to be flat (you can do both if you want the top flat, but drops are round).
Place about a ⅓ of the icing in a separate bowl, and working from this smaller amount (we’ll get back to the rest later – this is just to avoid getting crumbs in your icing) put a smooth later cross the top of the bottom layer.
Place the top layer on the bottom layer, and ice the top of the cake, and then the sides. This first coat should be fairly thin. Give it a few minutes to dry on the surface before proceeding with the second coat.
Using the rest of the icing, apply a thick final coat of icing, particularly on top.
Using the blueberries attempt to create a Drupal logo pattern on the top of the cake.
I didn’t get a picture of the inside so here’s another view of the logo – yes that’s supposed to be the Drupal 8 logo. Happy 1st birthday to Drupal 8.
During last month’s SCDUG I gave two presentations. I’ve already posted the Sins Against Drupal talk I gave. That didn’t take up much time, and since I had been prepping some thoughts on the first few Drupal 8 projects I gave a second short talk on what I’ve learned working with Drupal 8 during its first year.
What’s not new?
Drupal 8 brings forward lots of concepts from Drupal 7 (and prior versions). It also brings forward a few standard community realities.
The information architecture tools are basically the same at least at the conceptual level. Nodes, Fields, Taxonomy, and Menus all still exist more or less as we’ve known them for years, and while there are differences on the surface those differences are incremental in nature and scope.
We also still have the constant hunt for modules that do what you’re doing so you don’t reinvent the wheel. Many modules that people are used to using are still missing, but new things arrive daily, and many of the new versions are significant improvements over previous generations of tools.
And there is still a lack of a clear line between front-end and back-end. When does business logic end and interface begin? When does a themer need to understand Drupal’s HTML generation vs when does a backend developer need to figure out how to force Drupal to generate carefully crafted markup? There are opportunities to form better and clearer lines, but they aren’t automatic by any means: every team will have to solve this problem their own way.
What’s so great?
Drupal 8 opens up a collection of new tools and opportunities for the community.
As a backend developer you get to write modern code. The name spacing can feel a little Java-esc at times, but the ability to properly name space code, ditch globals, move from hooks to event listeners, and other basic OOP tools is incredibly nice.
With CKEditor in core we get better integration between that interface and the rest of Drupal. And better modules are coming out all the time to solve long standing UX annoyances. For example with the D8 Editor File upload module files and images can both be handled as Drupal file objects, but the editor can know the difference between a file (which should just be a link) and an image (which you should display).
The Symfony community provides a large number of packages that provide 3rd party integrations, or the tools to make them easy to build.
The two core base themes do not require keelhauling to make viable. If you commonly built your themes from scratch, the ability to have clean default markup that’s easy to override makes both Stable and Classy a major improvement to life.
Things you need to survive
As you dive into your first projects you need to understand that much of what you know at the detail level has changed. And so you’ll need to learn a few new tricks and be willing to toss aside a few old ideas:
Your old build standards are wrong. Probably not entirely, but you’ll need new modules in your default builds, new best practices about when to use a node vs block vs custom entities, and other basic details you probably have really well develop standards (or at least habits) from years of working with Drupal.
If you’ve been avoiding it to-date, it’s time to develop an understanding about composer, drush, and Drupal console. Not only do you need to be using these tools (probably all three) but you need to understand what each provides and which tool is best for which job.
Nginx is not for the faint of heart: as best I can find, no one has published a complete setup guide yet. In Drupal 6 and 7 there were pretty good guides to setting up Nginx properly, but with Drupal 8 there are enough differences that those guides don’t really work. And all the guides that I have read so far include errors (some of them significant security mistakes). To be clear, it can be done, but if you want to do it yourself be prepared to do a great deal of extra research along the way.
If you have windows you have pain. There are a number of windows specific challenges (speed and NTFS weakness being the biggest we face), and there is little community support to help you overcome the challenges.
Core patches tend to be required. Unlike Drupal 7, core and module patching is the norm not the exception. There are several issues that are frustratingly slow to get fixed that hit some fairly common use cases (like this menu block bug). While this is improving all the time, we haven’t launched a D8 site without at least one patch in place.
Cache tags are great, but require learning. The new caching system is powerful, flexible, and totally different from what we had before. It’s better, but to use it well you’ll need to spend some time getting to know when to set and clear the tags you want to create.
Twig is great, but requires learning and discipline. I really like twig and the much cleaner syntax to brings to the theme layer. However, as more and more people use it they are finding ways to move increasingly complex logic out of modules and theme PHP into template files. Please fight this urge! Keep your business logic separate from your display logic. If some object wasn’t loaded into a variable in your twig file do not attempt to load it in twig. If you need some 4 or 5 layer selector to get to the value you want to print: fix that in a preprocess function.
The API improvements are coming all the time and make things interesting. So far the community has stayed on schedule of rolling out new minor versions of 8 and that’s meant great new features in each version. It has also meant that sometimes a solution you built is not using the best techniques given the improvements. That’s not really a problem, but can add headaches in maintenance cycles. Also you will find places where brand new D8 tools are already deprecated but the replacements don’t have good example implementations yet.
XML to JSON in Five lines
In closing I want to share the feature that caused me to realize that Symfony was worth the cost of admission: a 5 line XML to JSON AJAX callback.
My first site had a location finder that links to a data provider partner locations nationwide. That provider has an XML-base API that cannot be accessed directly from browsers, and therefore needed to be proxied through the main site. The full details involve more than just the following lines of code (providing input checking, settings, routing, etc), but the heart of the process is just five lines.
$client = new Client(); // 1: Create Guzzle Client
try{
$res = $client-&gt;get($config-&gt;get('api_endpoint'), // 2: Make request
[
'http_errors'=&gt;false,
'query' =&gt;; [
'key'=&gt; $config-&gt;get('coop_api_key'),
// ...
],
]);
$decoderRing = new XmlEncoder(); // 3: Create XML Encoder
$xml = $decoderRing-&gt;decode($res-&gt;getBody()); // 4: Decode the XML Response into an array.
return new JsonResponse($xml); // 5: Return the array as JSON
} catch (RequestException $e) {
throw new HttpException($this-&gt;t('Unable to process request'));
}
This is part of my ongoing series about ways Drupal can be badly misused. These are generally times someone tried to solve an otherwise interesting problem in just about the worst possible way. All of these will start with a description of the problem, how not to solve it, and then ideas about how to solve it well.
I present these at SC Drupal Users Group meetings from time to time as an entertaining way to discuss ways we can all improve our skills.
This one was presenting during our October event here in Aiken, SC.
The Problem
Provide a custom authentication solution that allows staff to have one backend and members another.
The Sinful Solution
In order to force staff to use the staff login page, during login form validation check to see if the user is a staff member, by authenticating the user, checking their groups, and logging out staff.
The Code
/**
* Prevents staff members from logging in outside of staff login page. &amp;amp;lt;&amp;amp;lt;-- Why?
*/
function my_auth_staff_boot($form, &amp;amp;amp;$form_state) { // NOT actually a hook_boot (thankfully) called as login form validator...
user_authenticate($form_state['values']);
global $user;
if (in_array('An Employee', $user-&amp;amp;gt;roles)) {
form_set_error($form['#id'], l(t('Staff must log in via staff-login', 'staff-login')), TRUE);
drupal_set_message('Staff must log in via ' . l(t('staff-login', 'staff-login')), 'error', TRUE);
// Load the user pages in case they have not been loaded.
module_load_include('inc', 'user', 'user.pages');
user_logout();
}
}
Why is this so bad?
This code actually completes the login process before kicking the user out. Why would you ever want to do that to your users? What did they do to you? It also loads an extra file for no apparent reason just before kicking the user back out.
Better Solutions
The goal here is to control what backend the user logs into, and shouldn’t control the page they login from. So the place to look for solutions are modules that already do this and so I propose mimicking the LDAP or GAuth modules’ approaches. LDAP attaches a validator to the form and takes over authentication, but LDAP supports lots of options so the code there is too extensive to use for a clear example. So for discussion I pulled out elements of the GAuth module (although there is still lots of trimming to make this understandable).
The GAuth module adds a submit button to the form and handles all processing for that form directly.
/**
* Implements hook_form_alter().
*/
function gauth_login_form_alter(&amp;amp;amp;$form, &amp;amp;amp;$form_state, $form_id) {
if ($form_id == 'user_login' || $form_id == 'user_login_block') {
$form['submit_google'] = array(
'#type' =&amp;gt; 'submit',
'#value' =&amp;gt; t(''),
'#submit' =&amp;gt; array('gauth_login_user_login_submit'),
'#limit_validation_errors' =&amp;gt; array(),
'#weight' =&amp;gt; 1000,
);
drupal_add_css(drupal_get_path('module', 'gauth_login') . '/gauth_login.css');
}
}
/**
* Login using google, submit handler
*/
function gauth_login_user_login_submit() {
if (variable_get('gauth_login_client_id', FALSE)) {
// .. skipping resource validation ...
$client = new Google_Client();
// .. skipping client setup ...
$url = $client-&amp;gt;createAuthUrl();
// Send the user off to Google for processing
drupal_goto($url);
}
// ... skip errors
}
From there we pass through a menu router from the main module, and an API hook to get:
function gauth_login_gauth_google_response() {
if (isset($_GET['state'])) {
// Skipping some error traps...
$redirect_url = isset($state['destination']) ? $state['destination'] : '';
if (isset($_GET['code'])) {
// Skipping a bunch of Client setup...
$oauth = new Google_Service_Oauth2($client);
$info = $oauth-&amp;amp;gt;userinfo-&amp;amp;gt;get();
if ($uid = gauth_login_load_google_id($info['id'])) {
$form_state['uid'] = $uid;
user_login_submit(array(), $form_state); // &amp;lt;&amp;lt; That right there with the $form_state['uid'] set does the magic.
}
else {
// Skipping other options....
}
}
drupal_goto($redirect_url); // &amp;amp;lt;&amp;amp;lt; be nice and handle the destination parameter
}
}
Share your sins
I’m always looking for new material to include in this series. If you would like to submit a problem with a terrible solution, please remove any personally identifying information about the developer or where the code is running (the goal is not to embarrass individuals), post them as a gist (or a similar public code sharing tool), and leave me a comment here about the problem with a link to the code. I’ll do my best to come up with a reasonable solution and share it with SC DUG and then here. I’m presenting next month so if you have something we want me to look at you should share it soon.
If there are security issues in the code you want to share, please report those to the site owner before you tell anyone else so they can fix it. And please make sure no one could get from the code back to the site in case they ignore your advice.
This is part of my ongoing series about ways Drupal can be badly misused. These examples are from times someone tried to solve an otherwise interesting problem in just about the worst possible way.
I present these at SC Drupal Users Group meetings from time to time as an entertaining way to discuss interesting problems and ways we can all improve.
This one was presented about a year ago now (August 2015). Since I wasn’t working with Drupal 8 when I did this presentation the solution here is Drupal 7 (if someone asks I could rewrite for Drupal 8).
The Problem
The developer needed to support existing Flash training games used internally by the client. Drupal was used to provide the user accounts, game state data, and exports for reporting. The games were therefore able to authenticate with Drupal and save data to custom tables in the main Drupal database. The client was looking for some extensions to support new variations of the games and while reviewing the existing setup I noticed major flaws.
The Sinful Solution
Create a series of bootstrap scripts to handle all the interactions, turning Drupal into a glorified database layer (also while you’re at it, bypass all SQL injection attack protections to make sure Drupal provides as little value as possible).
The Code
There was a day when bootstrap scripts with a really cool way to do basic task with Drupal. If you’ve never seen or written one: basically you load bootstrap.inc, call drupal_bootstrap() and then write code that takes advantage of basic Drupal functions – in a world without drush this was really useful for a variety of basic tasks. This was outmoded (a long time ago) by drush, migrate, feeds, and a dozen other tools. But in this case I found the developer had created a series of scripts, two for each game, that were really similar, and really really dangerous. The first (an anonymized is version shown below) handled user authentication and initial game state data, and the second allowed the game to save state data back to the database.
As always the script here was modified to protect the guilty, and I should note that this is no longer the production code (but it was):
&lt;?php
require_once './includes/bootstrap.inc';
drupal_bootstrap(DRUPAL_BOOTSTRAP_FULL); // "boot" Drupal
define("KEY", "ed8f5b8efd2a90c37e0b8aac33897cc5"); // set key
// check data
if(!(isset($_POST['hash'])) || !(isset($_POST['username'])) || !(isset($_POST['password']))) {
header('HTTP/1.1 404');
echo "status=100";
exit; // missing a value, force quit
}
// capture data
$hash = $_POST['hash'];
$username = $_POST['username'];
$password = $_POST['password'];
// check hash validity
$generate_hash = md5(KEY.$username.$password);
if($generate_hash != $hash) {
header('HTTP/1.1 404');
echo "status=101";
exit; // hash is wrong, force quit
}
// look for username + password combo
$flashuid = 0;
$query = db_query("SELECT * FROM {users} WHERE name = '$username' AND pass = '$password'");
if ($obj = db_fetch_object($query)){
$flashuid = $obj-&gt;uid;
}
if($flashuid == 0) {
header('HTTP/1.1 404');
echo "status=102";
exit; // no match found
}
// get user game information
$gamequery = db_query("SELECT * FROM {table_with_data_for_flash_objects} WHERE uid = '$flashuid' ORDER BY lastupdate DESC LIMIT 1");
if ($game = db_fetch_object($gamequery)){
$time = $game-&gt;time;
$round = $game-&gt;round;
$winnings = $game-&gt;winnings;
$upgrades = $game-&gt;upgrades;
} else {
// no entry, create one in db
$time = $round = $game_winnings = $long_term_savings = $bonus_list = "0";
$upgrades = "";
$insert = db_query("INSERT INTO {table_with_data_for_flash_objects} (uid, lastupdate) VALUES ('$flashuid',NOW())");
}
$points = userpoints_get_current_points($flashuid);
// echo success and values
header('HTTP/1.1 201');
echo "user_id=$flashuid&amp;points=$points&amp;ime=$time&amp;round=$round&amp;winnings=$winnings&amp;upgrades=$upgrades";
?&gt;
Why is this so bad?
It’s almost hard to know where to be begin on this one, so we’ll start at the beginning.
Bootstrap scripts are not longer needed and should never have been used for anything other than a data import or some other ONE TIME task.
That key defined in line 3, that’s used to track sessions (see lines 20-21). If you find yourself having to recreate a session handler with a fixed value, you should assume you’re doing something wrong. This is a solved problem, if you are re-solving it you better be sure you know more than everyone else first.
Error handling is done inline with a series of random error status codes that are printed on a 404 response (and the flash apps ignored all errors). If you are going to provide an error response you should log it for debugging the system, and you should use existing standards whenever possible. In this case 403 Not Authorized is a far better response when someone fails to authenticate.
Lines 15-17, and then line 30: a classic bobby tables SQL Injection vulnerability. Say goodbye to security from here on in. They go on to repeat this mistake several more times.
Finally, just to add insult to injury, the developer spends a huge amount of time copying variables around to change their name: $password = $_POST[‘password’]; $round = $game->round; There is nothing wrong just using fields on a standard object, and while there is something wrong with just using a value from $_POST, copying it to a new variable does not make it trustworthy.
Better Solutions
There are several including:
Use a custom menu to define paths, and have the application just go there instead.
Use Services module: https://www.drupal.org/project/services
Hire a call center to ask all your users for their data…
If I were starting something like this from scratch in D7 I would start with services and in D8 I’d start with the built-in support for RESTful web services. Given the actual details of the situation (a pre-existing flash application that you have limited ability to change) I would go with the custom router so you can work around some of the bad design of the application.
In our module’s .module file we start by defining two new menu callbacks:
function hook_menu() {
$items['games/auth'] = array(
'title' =&gt; 'Games Authorization',
'page callback' =&gt; 'game_module_auth_user',
'access arguments' =&gt; array('access content'),
'type' =&gt; MENU_CALLBACK,
);
$items['games/game_name/data'] = array( // yes, you could make that a variable instead of hard code
'title' =&gt; 'Game Data',
'page callback' =&gt; 'game_module_game_name_capture_data', // and if you did you could use one function and pass that variable
'access arguments' =&gt; array('player'),
'type' =&gt; MENU_CALLBACK,
);
return $items;
}
The first allows for remote authentication, and the second is an endpoint to capture data. In this case the name of the game is hard coded, but as noted in the comments in the code you could make that a variable.
In the original example the data was stored in a custom table for each game, but never accessed in Drupal itself. The table was not setup with a hook_install() nor did they need the data normalized since its all just pass-through. In my solution I switch to using hook_install() to add a schema that stores all the data as a blob. There are tradeoffs here, but this is a clean simple solution:
...
'fields' =&gt; array(
'recordID' =&gt; array(
'description' =&gt; 'The primary identifier for a record.',
'type' =&gt; 'serial',
...
'uid' =&gt; array(
'description' =&gt; 'The user ID.',
'type' =&gt; 'int',
...
'game' =&gt; array(
'description' =&gt; 'The game name',
'type' =&gt; 'text',
...
'data' =&gt; array(
'description' =&gt;'Serialized data from Game application',
'type' =&gt; 'blob',
...
You could also take this one step further and make each game an entity and customize the fields, but that’s a great deal more work that the client would not have supported.
The final step is to define the callbacks used by the menu items in hook_menu():
function game_module_auth_user($user_name = '', $pass = '') { // Here I am using GET, but I don’t have to
global $user;
if($user-&gt;uid != 0) { // They are logged in already, so reject them
drupal_access_denied();
}
$account = user_authenticate($user_name, $pass);
//Generate a response based on result....
}
function game_module_[game_name]_capture_data() {
global $user;
if($user-&gt;uid == 0) { // They aren’t logged in, so they can’t save data
drupal_access_denied();
}
$record = drupal_get_query_parameters($query = $_POST); // ← we can work with POST just as well as GET if we ask Drupal to look in the right place.
db_insert('game_data')
-&gt;fields(array(
'uid' =&gt; $user-&gt;uid,
'game' =&gt; '[game_name]',
'data' =&gt; serialize($record),
))
-&gt;execute();
// Provide useful response.
}
For game_module_auth_user() I use a GET request (mostly because I wanted to show I could use either). We get the username and password, have Drupal authenticate them, and move on; I let Drupal handle the complexity.
The capture data callback does pull directly from the $_POST array, but since I don’t care about the content and I’m using a parameterized query I can safely just pass the information through. drupal_get_query_parameters() is a useful function that often gets ignored in favor of more complex solutions.
So What Happened?
The client had limited budget and this was a Drupal 6 site so we did the fastest work we could. I rewrote the existing code to avoid the SQL Injection attacks, moved them to SSL, and did a little other tightening, but the bootstrap scripts remained in place. We then went our separate ways since we did not want to be responsible for supporting such a scary set up, and they didn’t want to fund an upgrade. My understanding is they heard similar feedback from other vendors and eventually began the process of upgrade. You can’t win them all, even when you’re right.
Share your sins
I’m always looking for new material to include in this series. If you would like to submit a problem with a terrible solution, please remove any personally identifying information about the developer or where the code is running (the goal is not to embarrass individuals), post them as a gist (or a similar public code sharing tool), and leave me a comment here about the problem with a link to the code. I’ll do my best to come up with a reasonable solution and share it with SC DUG and then here. I’m presenting next month so if you have something we want me to look at you should share it soon.
If there are security issues in the code you want to share, please report those to the site owner before you tell anyone else so they can fix it. And please make sure no one could get from the code back to the site in case they ignore your advice.




 Some time is more important than others, like outages.
Some time is more important than others, like outages.