
Loading large amounts of data into Salesforce is a non-trivial exercise. While traditional databases can often be loaded in nearly any order, or with just a few simple considerations for foreign keys, Salesforce’s platform behaviors require several special considerations.
Over the last few years I’ve done a number of large data migrations into Salesforce, and developed a pattern I like to follow. This pattern allows me to load data efficiently at any scale.While the implementation details will vary, you can adapt this pattern to your projects.
Efficiency matters more the larger your project: for a small project, this is overkill. If you are loading 1,000 Contacts it will probably take you longer to setup my process than just format the file in Excel and load it through Data Loader. But if you need to load 100’s of thousands of records, millions of records, across lots of different objects, this pattern can save hours or even days.
Migration Process Overview
The general concept here, is that you’ll run your migration in two major phases:
- Prepare the data in a staging database.
- Load the data into Salesforce.
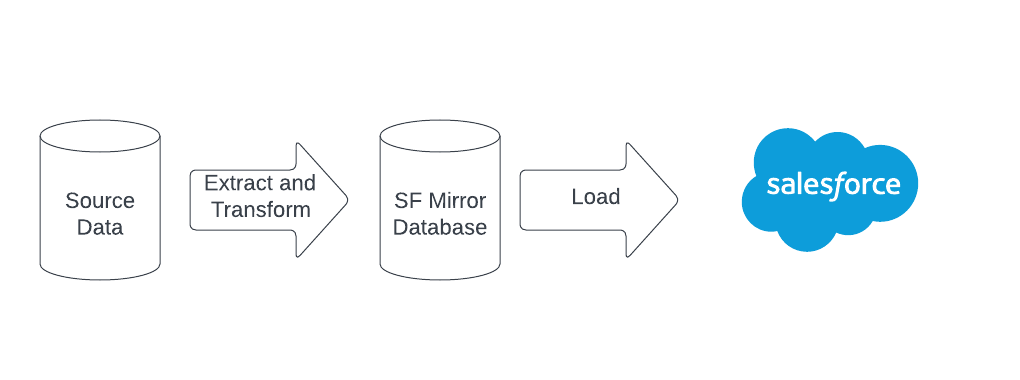
Salesforce Schema Mirror Staging Database
The key to this process is that staging database in the middle.
In my experience having a database that is a clone of Salesforce’s schema allows you to fully prepare the data prior to loading. It also gives you a source of truth when handling partially loaded data.
Salesforce is slow to load compared to most traditional databases. By having a staging database you can load fast, gives you a chance to insert steps into your process that are hard in other contexts. These steps allow for testing, speed-enhancements, and error recovery.
Some ETL tools make a staging database easy to build, others do not. If you aren’t sure how to build such a database (or it seems like a huge effort to re-create all those tables), you can use Salesforce2Sql – that’s why I created it. It will clone your Salesforce org’s schema into any of its supported databases.
Testing and Error Recovery
The staging database lets you test for errors after you do your initial conversion; before you load it into Salesforce. You can leverage reporting and scripting engines designed for that database. You can log and error trap during your loading process far more gracefully than the Salesforce APIs support by default.
I often add one more table than just the objects: a logging table. This allows me a place to write the rows from Salesforce error files, and also log the time it takes for each process to run. I can see exactly what errors my process encounters at the record level during testing, and measure the running time.
This database will also give you a place to trace what has, and has not, been loaded into Salesforce. More about how to implement this and drive performance to come.
Transform the Data
Using the tool of your choice, create a process to transform the data from the source data into your staging database. How you do this stage could be a series of posts by itself. For my ideas on a good process for this I suggest my Queries on Queries talk.
Your process will have a mountain of small details – I often describe it as “hard and boring”. Done well this is your best point in the process for testing your work. Test thoroughly! You should run this process so many times you lose count.
Salesforce Migration Keys
One important detail is that you will want to leave the main record Id field null. Your legacy Id goes into a legacy Id field, but the main Id field should be empty. We’ll use that in the loading stage to determine which records were successfully loaded and which need follow up attention.
Every object you are migrating should have a legacy Id field that links back to your source database. These should generally be text fields, set to be external Ids and unique. These fields will both help with the migration itself, but also the validation process – and should you need to, you will be able to update the data post-migration using those same keys.
To handle references between records use the legacy Ids as the lookup Id values. For example, on a Salesforce Contact there is an AccountId field to reference the parent account. The Account’s legacy Id should be in AccountId. Often this value is already in your foreign key fields so it can be a real time saver in your transformation build. We’ll see in a minute how we use those to resolve to new Salesforce Ids as we load data.
Data Cleaning
This is also the time and place to do whatever data cleansing you plan to do in your process. You can do that work post-launch as well (mostly). I highly recommend this cleansing be automated for large data sets. If you can’t automate it, do it pre-migration in your old system, or post-migration in Salesforce.
Pre-Load Data Validation
Using the staging database your transformed data can be fully validated before you load it.
- Check your references: Make sure all your lookup fields are populated with valid data.
- Check your record counts: Do you have the expected number of records in every table?
- Check your critical fields: All data points are created equal, but some are more equal than others. Check those a few extra times.
If you have the time and resources, you can write scripts and other automations to run these tests for you. The more the better.
Loading Salesforce
Finally, all that data you just transform and staged is ready for high volume loading. For each object you run two steps:
- Insert the data via the Bulk API (Insert not Upsert!), record the start and end time and all errors in your log table.
- Update the records in your staging database to add the new Salesforce Id into the source record’s Id column (the one I told you to leave blank before).
When there are no null values left in the Id column, you have loaded all your data. If there are records that refuse to load, for any reason, you will know because the Id will be null. If you logged the errors you can see why.
You will also use those Ids in later jobs to update the reference Ids. Remember, we put the legacy Id into your reference fields, when you actually load the data you need to replace that legacy Id with the actual Salesforce Id.
When possible you should build these load jobs to only load records without a Salesforce Id already assigned. That will allow you to safely re-run the job if it encounters errors that lead to partial success (like record locking, see below).
Why Not Upsert?
People used to loading small amounts of data will be tempted to use Salesforce’s upsert command. The benefit is that it allows you to use those legacy Id values directly instead of swapping for the newly generated Id. But as record volumes grow, upsert performance drops – I’ve had projects where I measured it at ⅓ the speed of insert, I heard of projects where it got far worse than that. The larger the dataset, the more important it is to use Insert.
Playing Nice with Salesforce
To make sure your data loads correctly, and efficiently, there are three more important details you still need to plan for:
- Automations and Sharing Rules
- Object Load Order
- Record Load Order
Automations and Sharing Rules
Automations take time to run, even small amounts of time add-up when loading large amounts of data. To the degree possible, you want automations off. Some automations you want to replicate in your transformation process – particularly if it’s a simple field value or record creation. Some automations you want to defer and run later, like custom roll up values via DLRS, NPSP rollups, or similar approaches. And some automations you cannot disable at all.
Sharing calculations in Salesforce are really a special-purpose automation. Just not one you often think about unless you’re doing manual sharing. Like all automations in Salesforce, the more data you load, the larger the impact of these calculations. Salesforce allows you to defer these calculations and run them in the future. The more complex your security setup, the more impact this will have (open security models can generally ignore this consideration).
The person doing the data loading needs to work with the folks that implemented those automations to map out which can be disabled, which can be deferred, and which must to be tolerated.
Object Load Order
In Salesforce, object load order is critical. You cannot disable or defer assignment of required references. So you need to understand the object hierarchy and relationships.
Generally you start with objects that have no dependencies: e.g. Account, Campaign, Product, Lead.
Then proceed to objects that have relationships to those: e.g. Contact
Then to objects that can have relationships to objects from that previous layer: e.g. Opportunity, Account Contact Relation, Campaign Member
When possible, test running two objects in parallel. What exact combination is most efficient will vary by org details and data volumes. My experience is that you will be able to run objects in 4-5 groups usually with two or three objects loading in parallel.
Ideally we’d just load records and not have to go back and update, but if there are circular references, or record hierarchies you’ll need to update records after insert. Plan that second pass into your sequence.
Users
Salesforce Users are a special case. If you have a security model where record ownership is important, you need to load Users first. If you have an open security model, I recommend loading Users last – and the smallest number of Users possible. Remember, Salesforce bans User deletion, so you must be as careful as possible about loading them. I never like to load Experience Cloud Users if I can avoid it – 1,000’s of accounts that will never be used but cannot be deleted is sub-optimal.
Record Load Order and Record Locks
Salesforce has aggressive record locking to deal with concurrent edits and updates across relationships. Great for day-to-day operation; frustrating when you’re loading data.
The first place people often encounter this is when they go to load Opportunities. Opportunity bulk load can run into massive problems with Account records being locked because another Opportunity is being loading for the same Account in a parallel process. If you sort the records by the locking parent record you can often reduce, if not eliminate, your record locking issues.
- Sort Contacts and Opportunities by Account.
- Sort Campaign Member by Campaign.
- Some Objects benefit from sorting by multiple fields: e.g. Tasks which you want to sort by WhoId and WhatId.
Use Serial Mode only as a last resort. Serial mode is ⅕ the speed of Parallel mode most of the time. There are situations that call for it. But it should never be your default go-to solution. Try everything else first before resorting to serial mode. Since you have tracking of which records were loaded or failed, if you design your load job carefully you can just re-run to resolve small numbers of record locks.
Extra Sorting Trick:
It turns out, in many cases the way data gets entered over time will gather it in useful patterns. So sorting data by a date field can radically reduce record lock contention. If you cannot figure out what field to sort by (often because sorting by field 1 causes locking issues on another object) try sorting by a date field and see if that helps.
Warning: depending on your data patterns, it can make the problem vastly worse too.
Mock Runs
A mock run is a test load into a sandbox that should involve you going through all the steps to load the data – starting with extracting it from the source system.
I personally recommend at least two full test mocks of your process.
If you’re working on a tight budget that may not be feasible (migrations are the first place project leaders trim budgets, and the first place users complain about errors), but that doesn’t mean multiple tests aren’t valuable.
The first test will go poorly, but you’ll learn a lot. The second test will, hopefully, go far better, but you will still learn a great deal.
In your testing you should expect to find places where your mappings are wrong, your transformations are incorrect, your testing is inadequate, your load order doesn’t work, you have source data patterns not accounted for, and more. Make time for good testing, you’ll thank yourself later.
Final Considerations
Large volume data loading in Salesforce is a deep topic. For all this is a long article, I’ve left out a lot of details. I designed this pattern to support high speed loads, rigorous testing, and error recovery. But within each of step of this pattern I could write articles this long or longer. You should continue to research the topic and adapt your implementation to your project.
A few sample topics you might consider:
- How to set audit fields.
- How to enable and disable triggers in production.
- Wipe and reload an org’s data.
You may even need to do something I’ve never encountered before.
But in any large volume Salesforce data load, the general pattern outlined here will serve you well.
