Kaylan Wagner – Real world lessons from online games.
This fall the South Carolina Drupal User’s Group started using Zoom are part of all our meetings. Sometimes the technology has worked better than others, but when it works in our favor we are recording the presentations and sharing them when we can.
In November Kaylan Wagner gave a draft talk on using experiences in the world of online gaming to be a better remote team member.
We frequently use these presentations to practice new presentations and test out new ideas. If you want to see a polished version hunt group members out at camps and cons. So if some of the content of these videos seems a bit rough please understand we are all learning all the time and we are open to constructive feedback.
If you would like to join us please check out our up coming events on Meetup for meeting times, locations, and connection information.
Chis Zietlow – Using Machine Learning to Improve UX
This fall the South Carolina Drupal User’s Group started using Zoom are part of all our meetings. Sometimes the technology has worked better than others, but when it works in our favor we are recording the presentations and sharing them when we can.
Chris Zietlow presented back in September about using Machine Learning to Improve UX.
We frequently use these presentations to practice new presentations and test out new ideas. If you want to see a polished version hunt group members out at camps and cons. So if some of the content of these videos seems a bit rough please understand we are all learning all the time and we are open to constructive feedback.
If you would like to join us please check out our up coming events on Meetup for meeting times, locations, and connection information.
For this month’s South Carolina Drupal User Group I gave a talk about creating Batch Services in Drupal 8. As a quick side note we are trying to include video conference access to all our meetings so please feel free to join us even if you cannot come in person.
Since Drupal 8 was first released I have been frustrated by the fact that Drupal 8 batch jobs were basically untouched from previous versions. There is nothing strictly wrong with that approach, but it has never felt right to me particularly when doing things in a batch job that I might also want to do in another context – that really should be a service and I should write those core jobs first. After several frustrating experiences trying to find a solution I like, I finally created a module that provides an abstract class that can be used to create a service that handles this problem just more elegantly. The project also includes an example module to provide a sample service.
Some of the text in the slides got cut off by the Zoom video window, so I uploaded them to SlideShare as well:
To define a batch you generate an array in a particular format – typically as part of a form submit process – and pass that array to batch_set(). The array defines some basic messages, a list of operations, a function to call when the batch is finished, and optionally a few other details. The minimal array would be something like:
The interesting part should be in that operations array, which is a list of tasks to be run, but getting all your functions setup and the batch array generated can often be its own project.
Each operation is a function that implements callback_batch_operation(), and the data to feed that function. The callbacks are just functions that have a final parameter that is an array reference typically called $context. The function can either perform all the needed work on the provided parameters, or perform part of that work and update the $context['sandbox']['finished'] value to be a number between 0 and 1. Once finished reaches 1 (or isn’t set at the end of the function) batch declares that task complete and moves on to the next one in the queue. Once all tasks are complete it calls the function provided as the finished value of the array that defined the batch.
The finish function implements callback_batch_finish() which means it accepts three parameters: $success, $results, and $operations: $success is true when all tasks completed without error; $results is an array of data you can feed into the $context array during processing; $operations is your operations list again.
Those functions are all expected to be static methods on classes or, more commonly, a function defined in a procedural code block imported from a separate file (which can be provided in the batch array).
My replacement batch service
It’s those blocks of procedural code and classes of nothing but static methods that bug me so much. Admittedly the batch system is convenient and works well enough to handle major tasks for lots of modules. But in Drupal 8 we have a whole suite of services and plugins that are designed to be run in specific contexts that batch does not provide by default. While we can access the Drupal service container and get the objects we need the batch code always feels clunky and out of place within a well structured module or project. What’s more I have often created batches that benefit from having the key tasks be functions of a service not just specific to the batch process.
So after several attempts to force batches and services to play nice together I finally created this module to force a marriage. Even though there are places which required a bit of compromise, but I think I have most of that contained in the abstract class so I don’t have to worry about it on a regular basis. That makes my final code with complex logic and processing far cleaner and easier to maintain.
The Batch Service Interface module provides an interface an an abstract class that implements parts of it: abstract class AbstractBatchService implements BatchServiceInterface. The developer extending that class only needs to define a service that handles generating a list of operations that call local methods of the service and the finish batch function (also as a local method). Nearly everything else is handled by the parent class.
The implementation I provided in the example submodule ends up four simple methods. Even in more complex jobs all the real work could be contained in a method that is isolated from the oddities of batch processing.
<?php
namespace Drupal\batch_example;
use Drupal\node\Entity\Node;
use Drupal\batch_service_interface\AbstractBatchService;
/**
* Class ExampleBatchService logs the name of nodes with id provided on form.
*/
class ExampleBatchService extends AbstractBatchService {
/**
* Must be set in child classes to be the service name so the service can
* bootstrap itself.
*
* @var string
*/
protected static $serviceName = 'batch_example.example_batch';
/**
* Data from the form as needed.
*/
public function generateBatchJob($data) {
$ops = [];
for ($i = 0; $i < $data['message_count']; $i++ ) {
$ops[] = [
'logMessage' => ['MessageIndex' => $i + 1],
];
}
return $this->prepBatchArray($this->t('Logging Messages'), $this->t('Starting Batch Processing'), $ops);
}
public function logMessage($data, &$context) {
$this->logger->info($this->getRandomMessage());
if (!isset($context['results']['message_count'])) {
$context['results']['message_count'] = 0;
}
$context['results']['message_count']++;
}
public function doFinishBatch($success, $results, $operations) {
drupal_set_message($this->t('Logged %count quotes', ['%count' => $results['message_count']]));
}
public function getRandomMessage() {
$messages = [
// list of messages to select from
];
return $messages[array_rand($messages)];
}
}
There is the oddity that you have to tell the service its own name so it can bootstrap itself. If there is a way around that I’d love to know it. But really one have one line of code that’s a bit strange, everything else is now fairly clear call and response.
One of the nice upsides to this solution is you could write tests for the service that look and feel just like any other services tests. The methods could all be called once, and you are not trying to run tests against a procedural code block or a class that is nothing but static methods.
I would love to hear ideas about ways I could make this solution stronger. So please drop me a comment or send me a patch.
Related core efforts
There is an effort to try to do similar things in core, but they look like they have some distance left to travel. Obviously once that work is complete it is likely to be better than what I have created, but in the meantime my service allows for a new level of abstraction without waiting for core’s updates to be complete.
In software just about all project management methodologies get labeled one of two things: Agile or Waterfall. There are formal definitions of both labels, but in practice few companies stick to those definitions particularly in the world of consulting. For people who really care about such things, there are actually many more methodologies out there but largely for marketing reasons we call any process that’s linear in nature Waterfall, and any that is iterative we call Agile.
Failure within project teams leading to disasters is so common and basic that not only is there a cartoon about it but there is a web site dedicated to generating your own versions of that cartoon (http://projectcartoon.com/).
Among consultants I have rarely seen a company that is truly 100% agile or 100% waterfall. In fact I’ve rarely seen a shop that’s close enough to the formal structures of those methodologies to really accurately claim to be one or the other. Nearly all consultancies are some kind of blent of a linear process with stages (sometimes called “a waterfall phase” or “a planning phase”) followed by an iterative process with lots of non-developer input into partially completed features (often called an “agile phase” or “build phase”). Depending on the agency they might cut up the planning into the start of each sprint or they might move it all to the beginning as a separate project phase. Done well it can allow you to merge the highly complex needs of an organization with the predefined structures of an existing platform. Done poorly it can it look like you tried to force a square peg into a round hole. You can see evidence of this around the internet in the articles trying to help you pick a methodology and in the variations on Agile that have been attempted to try to adapt the process to the reality many consultants face.
In 2001 the Agile Manifesto changed how we talk about project management. It challenged standing doctrine about how software development should be done and moved away from trying to mirror manufacturing processes. As the methodology around agile evolved, and proved itself impressively effective for certain projects, it drew adherents and advocates who preach Agile and Scrum structures as rigid rules to be followed. Meanwhile older project methodologies were largely relabeled “Waterfall” and dragged through the mud as out of date and likely to lead to project failure.
But after all this time Agile hasn’t actually won as the only truly useful process because it doesn’t actually work for all projects and all project teams. Particularly among consulting agencies that work on complex platforms like Drupal and Salesforce, you find that regardless of the label the company uses they probably have a mix linear planning with iterative development – or they fail a lot.
Agile works best when you start from scratch and you have a talented team trying to solve a unique problem. Anytime you are building on a mature software platform you are at least a few hundred thousand hours into development before you have your first meeting. These platforms have large feature sets that deliver lots of the functionality needed for most projects just through careful planning and basic configuration – that’s the whole point of using them. So on any enterprise scale data system you have to do a great deal of planning before you start creating the finished product.
If you don’t plan ahead enough to have a generalized, but complete, picture of what you’re building you will discover very large gaps after far too many pieces have been built to elegantly close them, or your solution will have been built far more generically than needed – introducing significant complexity for very little gain. I’ve seen people re-implement features of Drupal within other features of Drupal just to deal with changing requirements or because a major feature was skipped in planning. So those early planning stages are important, but they also need to leave space for new insights into how best to meet the client’s need and discovery of true errors after the planning stage is complete.
Once you have a good plan the team can start to build. But you cannot simply hand a developer the design and say “do this” because your “this” is only as perfect as you are and your plan does not cover all the details. The developer will see things missed during planning, or have questions that everyone else knows but you didn’t think to write down (and if you wrote down every answer to every possible question, you wrote a document no one bothered to actually read). The team needs to implement part of the solution, check with the client to make sure it’s right, adjust to mistakes, and repeat – a very agile-like process that makes waterfall purists uncomfortable because it means the plan they are working from will change.
In all this you also have a client to keep happy and help make successful – that’s why they hired someone in the first place. Giving them a plan that shows you know what they want they are reassured early in the project that you share their vision for a final solution. Being able to see that plan come together while giving chances to refine the details allows you to deliver the best product you are able.
Agile was supposed to fix all our problems, but didn’t. The methodologies used before were supposed to prevent all the problems that agile was trying to fix, but didn’t. But using waterfall-like planning at the start of your project with agile-ish implementation you can combine the best of both approaches giving you the best chances for success. We all do it, it is about time we all admit it is what we do.
Like last year I’m keeping an extremely rough setup of notes from DrupalCon as a repository of things I’m picking up and tracking of sessions that looked like they would be interested but that I couldn’t attend because I was in another session. I’ll clean then up a bit and add to them over time.
Thank you to everyone who worked so hard to make the event a success.
I’ve assembled a playlist of the various sessions I though were good when I attended, or looked good but couldn’t attend.
Monday I attended the Community Summit, and while I had lots of great discussions, I didn’t take a lot of notes. The biggest two things I noted were that Western New York DUG is doing interesting stuff with online meetings that might be worth checking out and emulating for the SC DUG. And that Mid-Camp keeps a list of all the various channels that have videos of Drupal Camp sessions.
DriesNote:
Roadmap:
The current roadmap looks pretty cool, assuming everything comes together as well as we all hope it will:
JS modernization and a new admin interface design are on their way, media library is part of that, but is likely a year out from being ready for prime-time.
Webchick summed this section of the talk nicely:
So rad to see the Out-of-the-Box and Layout initiatives being shown off together. Feels like #drupal 8 is really coming together for site builders and content authors! #driesnote#drupalcon
My read is that its well intended and has some ground to cover is it gets revised. I haven’t done a deep dive into its details yet, nor the response, but early reviews are mixed.
Frankly that Values statement leaves me a little cold. “Treating others with dignity and respect” !== “Creating a safe and inclusive community” #Driesnote#drupalcon
This was a really good session on accessibility with both a real world set of examples and realistic discussions of what’s hard and what happens when things pass tests but don’t get tested by humans.
Major take aways:
Modern tools support JS and it no longer gets in the way of accessibility. WCAG 1.0 said this was a problem 20 years ago, but that’s not the current best practice.
There are constraints to the work because of accessibility, but it they don’t have.
“There are times that I go to use an interactive calendar on the web and all I hear is 1, 2, 3, 4, 5, 6, 7, 8, 9, and so on to 30 or 31…with no indication that these are dates…just a mass of numbers in the middle of the page.”
We used to test sites by disabling CSS/JS. Now it makes more sense to try to navigate the site with a keyboard and see what happens. Remember that just because something is possible it doesn’t mean it’s obvious or good. This doesn’t get you to a great site, but allows you to pick off errors before someone finds them for you later.
When you tab to things, the visual affordances some designers hate can be put back in as a compromise for people using accessibility tools.
I need to spend more time with the iPhone voice over tool so I can test things better.
This was a really interesting session on the Material Admin theme, and what’s been needed to make it work. It’s not perfect, and may or may not be ready for prime-time, but it looks like a great idea and show what we can do to make the admin much better.
We’re behind, some of fixing that is easy, some of fixing that is hard.
When you’re UX is bad, people perceive things to be slow even if they aren’t. People think that material theme is faster even though it is demonstrably not.
Growth and survival of the project require us to have a better admin.
He’s trying to make sure add-ons for the theme/module are pretty standalone and just work. But theme’s can’t require modules which is silly.
Contenta uses Material by default on front and back because it provides decoupling well.
PDFs in Drupal (I was surprised that this one was overcrowded)
Salesforce BOF:
This BOF was a chance for Cornell to show off some great stuff they have been doing with Message Agency. They have done some cool stuff that shows the power for D8 and a good Salesforce integration.
It should go without saying, but it needs saying too much:
A Salesforce is a CRM. Drupal is a CMS.
Use your tools for what they are best at.
The content in Drupal, actions recorded back into Salesforce.
Lessons:
1) Know strengths of each tool
2) Understand user needs
3) Determine how you will use each tool
4) Get the details right: SSO, Data Mapping, etc.
Drupal is much better at providing accessibility, including Form Assembly which is hard. The SF eco-system is mixed on the whole.
One option for multiple databases is Snap Logic (apparently it is “capital intensive”).
This was a mini session that is worth watching if you’re unsure about the importance and value of having a code of conduct. The hope had been to have a discussion about the importance of Drupal’s CoC, but everyone who attended largely agreed about the broad strokes of the major issues that have been discussed lately in the community. We ended up talking more about how to broaden the discussion than about the CoC itself.
This session was an interesting look at the impact on ACLU’s D6 (yes that’s right) advocacy site running on Pantheon.
Moved to Pantheon in 2013. And that move dealt with limits of their old hosting solution. Unfortunately some of my old-timey knowledge of why that had that solution was so old they couldn’t tell me much about how they had managed to make that move.
“Crazy things happen all the time”
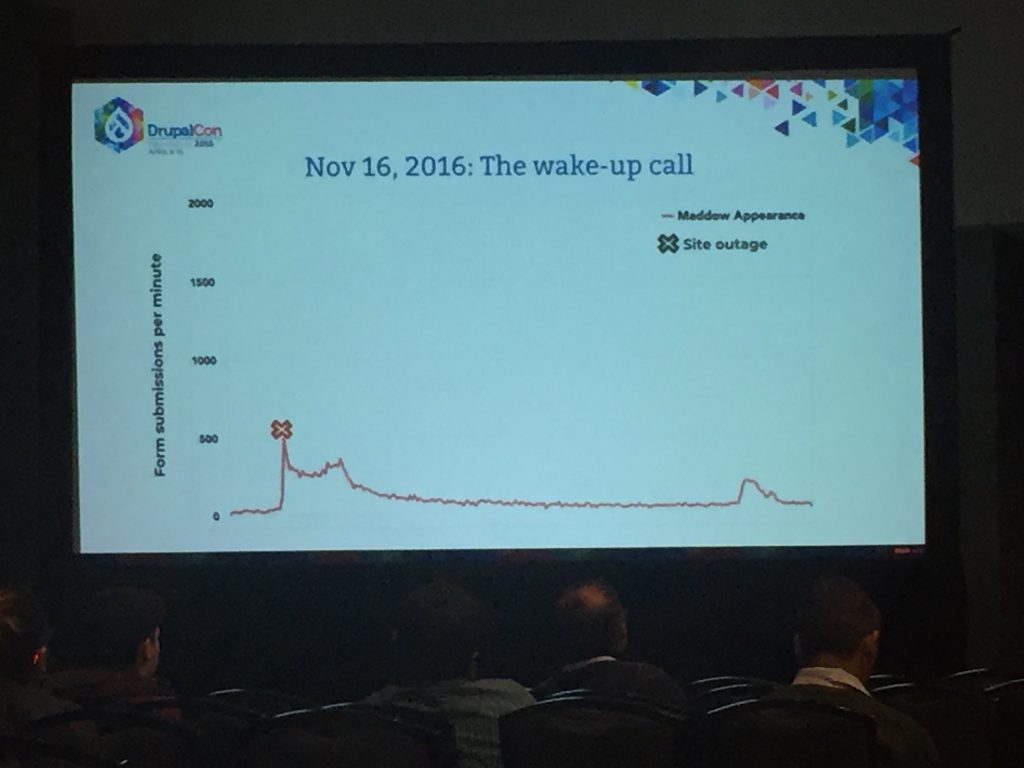
After the their ED made a Rachel Maddow appearance on 11/16/16 they saw an 85x traffic spike. Tag1 was called in to help sort out what happened.
Traffic spiked to just over 500 requests per minute during the interview.
They found it was database bound, which was very common on D6, but still something they see frequently.
Found queries with 3 table join with no indexes on the base table. Able to go from 200,000 rows being scanned, down to 76. They were responding in real-time in crisis response mode.
After the wave passed, they called Pantheon to help build out environments for testing using multi-dev.
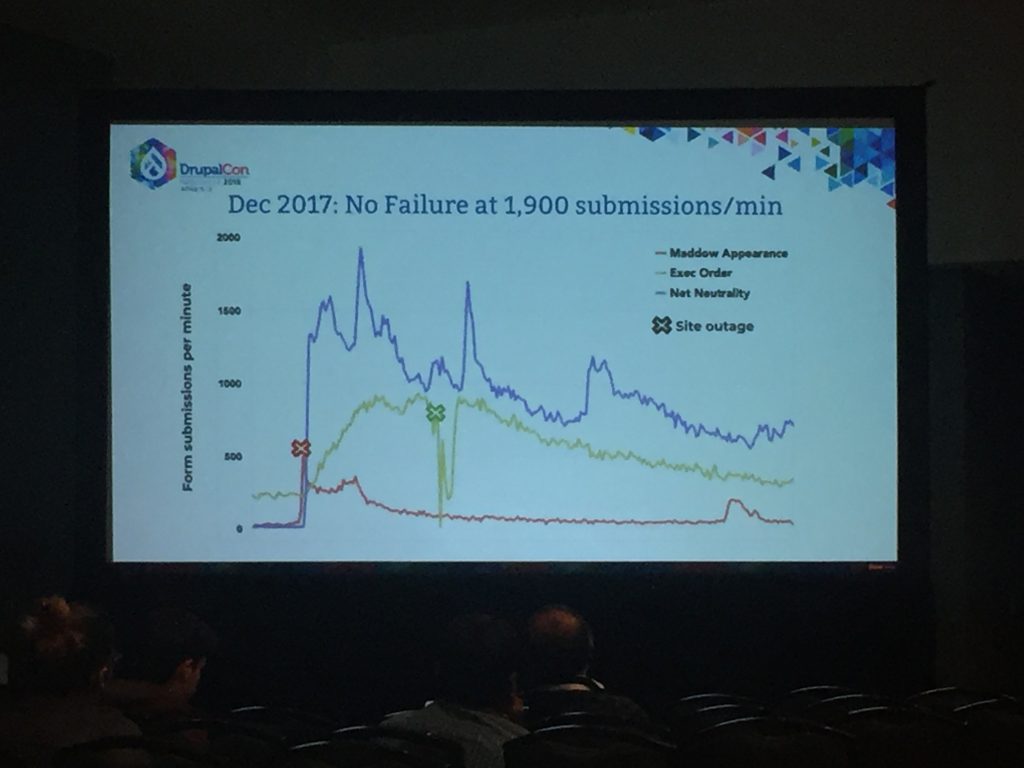
During the spikes that followed for the first travel ban, which were even larger they worked to reroute errors to Fastly, which served a PayPal fundraising link: at least the donations kept coming but that wasn’t good enough.
They needed a botnet to replicate the traffic. Tag1 used: Locust to create load tests, SaltStack to organize the bots, and EC2 to be the bots. They were failing at ~600 requests per minute and they were able to get to ~5,000 requests per minute. At that point the payment gateways were also starting to buckle, which isn’t a thing most people see.
The final wave they discussed came after the Net Neutrality lose, which peaked around 1,900 form submissions/min.
ACLU needed more logging, but didn’t want them logging personal information. Turned out the payment gateway’s CDN was detecting a DDOS and blocking them. See curl_log and curl_loadbalance. They also intentionally shift load from MySQL to Redis and PHP(?!?) because they knew Pantheon could scale that are far and as fast as needed to handle the waves, but MySQL was a limiting factor.
Things he argues we pioneered in Open Source:
– Distributed leadership
– Collabortive Development
– Community Engagement
Biggest lessons/takeaways from #Drupal for other open source communities: distributed development, collaborative development, community engagement. #DrupalCon
Interesting to reflect that its about the process and the community, but not about the technology.
Unrelated:
“Who here believes Facebook is unethical?” [hands rise] “Okay, who here has added a tracking pixel to a site at a client’s request?” [hands sheepishly rise] “Okay, now we return to the trolley problem…”
(Note: recording was intentionally stopped after the presentation but the discussion continued for quite a while).
Following Con last year Whitney Hess put forward some ideas, but it wasn’t clear where to go next.
It wasn’t clear that the DA should lead this, so it fell to the CWG cause they were last group standing.
Take aways:
Governance should evolve over time.
Need a values statement
Need to define the community and its membership.
Clearly document that structures and procedures.
CWG needs to improve CoC and enforcement.
Community needs to improve its global outreach.
DA should set higher standards.
Community matters should escalate to groups, not individuals.
We need community onboarding.
We should engage with other communities to discover best practices.
What’s Happened:
Dries stepped down as DA board chair.
DA hired Rachel Lawson.
DA created an updated CoC.
Dries is doing a round table on Thursday.
What’s Next:
Trying to figure that out…
Need to determine if good feedback was gathered so far.
Need to figure out an ongoing and continuous feedback process.
The expected frustrations with Dries and the values statement were expressed. Communication between Dries and other folks continues to be a challenge. The bottleneck of single point of contact is making it hard to stop having a single point of contact.
The main discussion centered around what’s holding back D8 adoption and the ongoing sense that the main forces in the Drupal community no longer concern themselves with the nonprofit sector. This year’s BOF was small because NTC started today in New Orleans. From a rough head count if the people I new were in New Orleans had been at the BOF there would have been a similar number of people.
In 2013 51% of internet traffic was “non-human”. SEO industry calls it NHT. By 2014 it was 61%.
Humans can have superpowers – we have very real opportunities to improve our quality of life, our safety and accessibility or knowledge and resources. #DrupalCon@Amorelandra
Automatic’s Support of Camps and staff to do so: It’s great, but it’s not in the budget (DA budget). He talked about creating it as a DA service that could be self-sustaining, but the WordPress model includes a donation of 8 FTEs.
Yes!! Yes!! Let’s get the drupal al camp organizers together and hash it out!! We can do it! Likes camp organize sprint!! #drupalcon#AskDries@kaleemclarkson
What if your responsible for 1000 D7 sites? When we will know when there is a concrete answer to the question of the EOL for D7: This is an open issue without a good answer that needs a good answer. Move to D8? (but he doesn’t understand why that’s laughable without more detail).
What about the small shops and builders: He doesn’t feel like they were really left behind. Rachel also checked to what the DA could have done better with the new home page, but the language wasn’t a great choice.
"I don't think we're going to beat a Wix or a Squarespace. … Squarespace is really good at page-building, and we can look at them for inspiration. … We can do page-building that plays to our strength, like structured content."@Dries#AskDries#DrupalCon
What can a consumer do to preserve the open web: Not use Facebook. People read the web through Facebook like they do with Google. Don’t install an ad blocker.
Why don’t you hear more about Diversity issues from you? It’s important, and we have to do better. We aren’t were we should be, and I’m happy to show more leadership. I could do more by talking more about it in public and on twitter. Wants to think more about it, and doesn’t feel like an expert. He acknowledged his mistake in the DriesNote in Copanhagen. He also commented about shuttingdown after being called out because of how it was done. Wants understanding of the fact that he’ll make mistakes.
"Why don't you engage more in diversity and inclusion things online?" —@aburke626
"We need to do better, frankly. I'm happy to show more leadership there. … I can certainly do more. I'm going to take you up on that, you have my promise."
When are we moving to Github? A proof of concept is in place to move to GitLab! Our tools are better than GitLab in many ways, but GitLab wants to have our better strengths in their code base. So they are working on doing that for us and for all their users.
Is Drupal 7 Dead? No. Most sites are Drupal 7, and some new sites still launch there. But all the innovation is on 8.
Q: "Is Drupal 7 dead? Releases have slowed down…"@Dries: "Drupal 7 isn't dead…but I think a lot of the innovation has shifted to Drupal 8. People are still launching new websites on Drupal 7, and that's fine."#AskDries#Drupalcon
The new values and principles need work to more fully reflect the community. The process: a group together in December to review the community feedback. And it was clear he needed to do this. He’s been working on it since then, and has found it hard work. He wanted to make it Collabortive, but also wanted to put a stake in the ground. He knows that it needs work, but isn’t entirely sure of the next steps. Doesn’t want to the single owner. He would like to assemble a working group with a charter.
.@dries: "As a next step we're going to put together a working group…a diverse committee of people that can actually take it from here and carry it forward. My next step is to put together a charter for this group."#AskDries#DrupalCon
There were other CMSes in the world, but they were a shit show. I was working on the Linux kernel and liked the modular nature.
Why do you think people are hesitant to update their site? Decided to elect minor updates not major. Mostly that it add complexity.
Q: Why do you think Drupal sites are hesitant to upgrade [minor] releases?
A: "We do add new features in minor releases…that's been a challenge. We've been trying to evolve our releases, trying not to break things." —@Dries#AskDries#DrupalCon
Will the new principles state that destructive beliefs, not just actions, will be banned. He defers to the working group.
Someone just asked if Drupal should police the "toxic beliefs" of community members. #askdries/@Dries has no, repeat no credibility on this topic as he was completely and totally complicit and responsible in the botched @Crell affair.
Rachel acknowledged the tweet, but didn’t know what to do with the fact that it actually called her out. “I wasn’t paying attention.” and then blamed questioners for not asking questions earlier. @drnikki was given a space, and directed people to DD&I meetings.
A really bad response from the audience calling on women lead. Tim Plunket responded appropriately.
"It's the responsibility… of the people in power and the people with privilege and the position and the voice to do this work for everyone else. I don't think it's fair to blame [under-represented people]" —@timplunkett#AskDries#DrupalCon
“Including people in community is more than saying, ‘you’re all included!’ A lot. It’s in our language and our symbols and how we present ourselves and how that communicates ‘what we do here’ to people who are watching.” @blackamazon at #DrupalCon
The next installment in my ongoing set of posts to create a public record for things I couldn’t learn in one Google search is a process for using composer to track a Drupal 8 module in a private repository.
It’s pretty common for Drupal agencies to have a small collection of modules they have built in-house and use on nearly all client sites, or to build a module for one client that has many sites. We are all becoming adept at managing our projects with Composer, but the vast majority of resources are focused on managing publicly available code via packagist. There are times these kinds of internally shared modules cannot be made fully public (for example they may contain IP belonging to the client). We have one such client that needs a module deployed to dozens of sites, and so I sat down a few weeks ago to figure out a solution.
We use Bitbucket for our private repositories, I am sure there is a similar solution using GitHub, but I haven’t worked out its details.
Create private repo for module on Bitbucket.
Clone that repo locally, and structure it to match Drupal.org’s conventions (this probably isn’t required, but should allow your module to blend into the rest of the project more smoothly).
Now just run composer require client/client_private_module, and provide the oauth creds from step 3 (note: the first time you do this composer will create the needed ~/.composer/auth.json)
One of the best practices for Drupal 8 that is still emerging is how to create modules with complex deployable configuration. In the past we often abused the features module to do this, and while that continues to be an option, with Drupal 8’s vastly improved configuration management options and the ability to install configuration easily I have been looking for something better. I particularly want to build modules that don’t have unnecessary dependencies but I can still reliably include all the needed configuration in my project. And after a few tries I think I’ve struck on an effective process.
Let’s start with a quick refresher on installing configuration for a Drupal 8 module. During module installation Drupal will load any yaml files that match configuration patterns it already knows about that are included in your module’s config/install directory. In theory this is great but if you want to include configuration that comes with other modules you have to figure out what files are needed; if you want to include configuration from core modules you probably will need to find a fairly large collection files to get all the required elements. Finding all those files, and copying them quickly and easily is the challenge I set out to solve.
My process starts with a local development sandbox site that is just there to support this development work, and I create a local git repository for the site’s configuration (I don’t need to connect it to a remote, like Bitbucket or GitHub, or handle all of the site’s code since it’s just to support finding changes to config files). Once installation and any base configuration is complete I export the site’s config to the directory covered by the repo (here I used d8_builder/config/sync, the site itself was at d8_builder/pub), and make sure all changes in the repository are committed:
Now I create my module and a second repository just for it. The module’s repository is linked to a remote since this is the actual product I’m creating.
With that plumbing in place I can to make whatever configuration change I need included in the module. Lately I’ve been creating a custom moderation workflow with several user roles and edge cases that will need to be deployed on a dozen or so sites, so you’ll see that reflected below, but this process should work for just about any project with lots of interrelated configuration.
Once I have completed a set of changes, I export the site’s configuration again making sure to avoid uuids and hashes that will cause trouble on import: drupal config:export --remove-uuid --remove-config-hash
Now git can easily show which configuration files were changed, added, or removed:
Next I use git, xargs, and cp to copy those files into your module (hat tip on this detail to Andy Gregorowicz): git ls-files -om --exclude-standard --exclude=core.extensions.yml | xargs -I{} cp "{}" pub/modules/custom/fancy_workflow/config/install/
Notice that I skip the core.extensions.yml file. If your module had dependencies you’ll still need to update your module’s info.yml file to list them.
Now a quick commit and push of the changes to the module’s repo, and I’m ready to pull the module into other projects. I also commit the builder repo to ensure it’s easy to track any future changes.
This isn’t a replacement for tools like Configuration Installer, which are designed to handle an entire site, this is intended just for module development.
If you think you have a better solution, or that I’m missing something important please let me know.
I recently completed a Drupal 8 project that required pulling data from a remote database. The actual data is not terribly complicated, so Drupal’s role in this case is mostly to provide an abstraction layer that converts the database into a (cacheable) JSON response. Pulling all the pieces together took a little more research and guessing than I expected so I figured I might save a few people time by writing it up. This is more of an intermediate than a beginner project and so I’m going to skip over lots of detail that important to making it all really work. To really understand what’s happening here you’ll want a basic understanding of Drupal 8’s controllers and database services.
What we’re doing here is creating a database service and a controller to provide a JSON endpoint. We’ll define the database connection, the Drupal service, and then the controller.
Drupal allows us to define database connections in the main settings file. This allows easy access to Drupal’s database services and query classes.
Connection Definition
The first step is to define the database connection in settings.php:
Next we need to create a new database service using the new connection information. Drupal core’s database service can be leveraged to connect to additional databases by just defining your new connection as a service in your module’s services.yml file.
Notice the arguments from the database service are the array keys (in reverse order) from the settings.php definition of the connection.
That’s all it takes to create a new service that wraps around your database.
The Controller
That service is all well and good as far as it goes, but if we want to actually to send the data to the browser we need a controller to leverage our new service and send the response.
Using dependency injection I attached the service to the controller and it looked like it worked great.
<?php
/**
* Constructs a new DataSearchController object.
*/
public function __construct(ConfigFactory $config_factory, Connection $dataservice) {
$this->config = $config_factory->get('mydataservice.datasettings');
$this->database = $dataservice;
}
/**
* {@inheritdoc}
*/
public static function create(ContainerInterface $container) {
return new static(
$container->get('mydataservice.database')
);
}
public function getData(Request $request) {
$query = $this->database->select('mytable', 'mt');
// From here you gather your data and send your response...
}
In fact it did work flawlessly all the way through initial testing. Using the database service to get the data and the cacheable JSON response technique I’d worked out previously everything came together quickly. You could make a request of the controller with your search terms and the browser gets back a list of objects for display.
Then just before launch the client physically relocated the database server and didn’t tell us it would be offline. Turns out we hadn’t tested what happens to an injected database service when there is no response from the remote database server. The request would wait for the database connection to time out and then throw an exception that didn’t get handled in my code at all. There was no place to add a nice error message and it was incredibly slow since the timeout was 30 seconds.
So at the last minute I had two more problems to solve: trap the error and shorten the timeout on PDO connections.
Drupal 8 database services attempt their connection when the service itself created. It you use dependency injection that means exceptions need to be caught in create(). But create() cannot send a response to the browser, that has to happen later when the function that corresponds to the active route is called by the kernel.
My solution was to make the database service an optional parameter on the controller, and adjust the static returned by create based on the exception thrown:
<?php
/**
* Constructs a new DataSearchController object.
*/
public function __construct(ConfigFactory $config_factory, Connection $dataservice = null) {
$this->config = $config_factory->get('mydataservice.datasettings');
$this->database = $dataservice;
}
/**
* {@inheritdoc}
*/
public static function create(ContainerInterface $container) {
try {
return new static(
$container->get('config.factory'),
$container->get('mydataservice.database')
);
}
catch (\Exception $e) {
return new static(
$container->get('config.factory')
);
}
public function getData(Request $request) {
if (!$this->database) {
throw new HttpException(404, $this->config->get('database_offline_message'));
}
$query = $this->database->select('mytable', 'mt');
// From here you gather your data and send your response...
}
}
The other way to handle the exception would be to load the connection from Drupal’s service container when you need it in place of using dependency injection for that service.
Also, notice we’re throwing a 404 error. Ideally it would return a 5xx type error, but those trigger other behaviors that prevented me from providing nice errors for the JavaScript application to process easily. Our controller also had a page display (to send the JavaScript libraries and base markup for the actual interface on application startup), which meant that we needed to create a reasonably well themed response in that function as well:
So that fixed the errors, but still meant we had a really long wait for the database connection to time out before the connection error is even thrown in the first place. And now we come back to that PDO section of the database connection definition.
<?php
$databases['remote']['default'] = [
'database' => 'extra_data',
'username' => 'accessingUser',
'password' => 'UseGoodPasswordsIn2017&Beyond',
'prefix' => '',
'host' => '255.255.255.255',
'port' => '',
'namespace' => 'Drupal\\Core\\Database\\Driver\\mysql',
'driver' => 'mysql',
// Now is when I explain this
'pdo' => [
\PDO::ATTR_TIMEOUT => 5,
],
];
PDO expects you to override settings at connection time not in a settings file. So I couldn’t just update my PHP.ini and call it a day but I also couldn’t find any documentation on how to change any PDO settings. Leveraging the power of open source I started to follow the code paths, actually reading through how Drupal establishes MySQL connections and, found I it.
If you add a subarray in your connection definition keyed to ‘pdo’ Drupal will load and apply those settings instead of the defaults. There are a couple settings that Drupal insists on being right about for performance, stability, and security reasons, but timeout and many others are fair game.
Awhile back I wrote up a pattern for creating static blocks on Drupal 8 sites. This week I was working on a site where one of those blocks needs to be enabled or disabled on specific nodes at the discretion of the content author. To make this happen, I’m adding a new feature to my pattern.
In older versions of Drupal there were a number of ways to go, like the PHP Filter, or custom handling in the block’s view hook, but I figured there were probably more appropriate tools for this in Drupal 8. And I found what I needed in the Condition Plugin (more evidence that plugins are addictive). According to the change record they were designed to centralize a lot of the common logic used for controlling blocks, and I found it works quite nicely in this case as well (although a more generalized version might be useful).
I have the complete condition plugin at the end so you don’t have to get all the details exactly right as we go.
I started by adding a boolean field to the content type named field_enable_sidebar. Then I using drupal console generated the stub condition plugin:drupal generate:plugin:condition. In doing this the first time I also looked at the one defined in the core Node module to handle block visibility by content type.
The console will ask you a couple questions, obviously you can attach it to any module you’d like and call it whatever you’d like. For this example I have it in a fake module called my_blocks and the condition is named SidebarCondition. But the next couple questions are less obvious and more important.
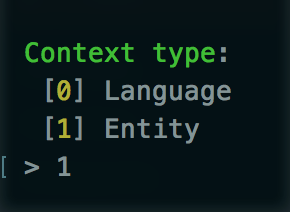
The context type should be set to entity since we are looking to work based on the node being displayed.
Next it’s trying to filter between entity types, and since we’re doing this based on the node content entity type, select “Content” to get a list of content entities on your site.
Finally select “Content” again since that’s the label for node entities in Drupal 8. If you have your field on another content entity type (like a taxonomy term, or a file), pick that entity here instead and rest of this should still work with minor editing.
Once you run through the wizard you’ll have a new file in your module: my_blocks/src/Plugin/Condition/sidebarContition.php
The condition plugin contains two main elements: a form that’s attached to all block settings forms, and an evaluate function that is called by blocks to determine if this condition applies in their current context.
buildConfigurationForm() defines the form array elements you need. In this case that means a simple checkbox to indicate that this condition applies to this block. We also need to define submitConfiguration() to save the values on block save.
public function buildConfigurationForm(array $form, FormStateInterface $form_state) {
$form['sidebarActive'] = [
'#type' => 'checkbox',
'#title' => $this->t('When Sidebar Field Active'),
'#default_value' => $this->configuration['sidebarActive'],
'#description' => $this->t('Enable this block when the sidebar field on the node is active.'),
];
return parent::buildConfigurationForm($form, $form_state);
}
public function submitConfigurationForm(array &$form, FormStateInterface $form_state) {
$this->configuration['sidebarActive'] = $form_state->getValue('sidebarActive');
parent::submitConfigurationForm($form, $form_state);
}
In the complete example you’ll see there is summary() which provides the human friendly description of the values that have been set for this condition.
Now let’s jump back to the top of the plugin and review the annotation. Conditions are annotated plugins and those questions I guided you through above were used to generate the annotation at the start of the file:
This is defining the context you’ll want passed to the condition for evaluation. In this case we are requiring that a node entity labeled “node” is provided when we need it.
The real work of the plugin is handled by evaluate():
/**
* Evaluates the condition and returns TRUE or FALSE accordingly.
*
* @return bool
* TRUE if the condition has been met, FALSE otherwise.
*/
public function evaluate() {
if (empty($this->configuration['sidebarActive']) && !$this->isNegated()) {
return TRUE;
}
$node = $this->getContextValue('node');
if ($node->hasField('field_enable_sidebar')&& $node->field_enable_sidebar-&amp;gt;value) {
return TRUE;
}
return FALSE;
}
The first conditional ensures that this plugin doesn’t disable all blocks that aren’t using it. Next we ask for the context node value we defined in the annotation, which provides us the current node able to be displayed. Since not all node types are guaranteed to have our sidebar field we first check that it exists and then check its value and return the correct status for block display.
Now every time a user checks a box on the node, any blocks with this condition enabled will be displayed along with the node. And the best part is that the user doesn’t need to even have block display permissions, we’ve allowed them to bypass that part of the system entirely.
A few weeks ago I wrote about not taking free t-shirts from vendors at DrupalCon (or other tech conferences). Well DrupalCon North America 2017 has come and gone so I thought I’d report back on this year’s t-shirts.
My free shirts from DrupalCon 2017
I ended up with seven new free shirts all from places that also offered them in women’s sizes. In addition to the official conference t-shirt I picked up shirts from Lingotek, Linode, Pantheon, Optasy, Chef.io, and Kanopi Studios. There were a couple companies that appeared to be giving out shirts I didn’t talk to so there may be a couple worthy of complementing that I missed. The big prize for the year goes to Linode whose job ad was a postcard in the shape of a (men’s) t-shirt and read:
Want a career in the cloud hosting industry? We’ve got a shirt in YOUR size.
Pantheon, as usual, had the most popular t-shirts with their custom printing shirts in a wide variety of sizes. That continues to be an amazing way to get people to watch their demo and collect contact information (although to be fair the demo itself is pretty amazing).
There were also a few companies that tried to convince me that bringing “unisex” shirts was the same as if they had brought women’s sizes.
Unisex shirts are, of course, just men’s shirts with a different label. And there are, of course, women who prefer the fit of that cut to shirts sold as women’s. But suggesting they work for everyone is just finding a new language for cheaping out. Arguably its worse than just forgetting that people come in different shapes since it shows someone thought about women looking for shirts but couldn’t be bothered to realize that most people want clothes that take into account their body shape. Ever met a guy who says he’s prefers how a woman’s cut shirt fits his body?
At least I didn’t hear anyone recommending using them as pajamas.









{kind=link}